高级教程1-实拍+AI的终极玩法,运镜不失真,背景随便换,教你做出电影级可控视频
这里是黑石宇的频道,第一期高级教程!
学习颠覆性的免费 AI 视觉特效工作流,
仅使用一张参考图像与 ComfyUI 中的 Wan 2.1. VACE,即可更换任何背景。
视频教程链接
部分效果预览






↓↓↓ 工作流和素材文件在文章最下方 ↓↓↓
工作流
顺序依然为从左到右,一共9个部分,有一定难度,需要反复多听多操作,掌握后,基本不会再有搞不定的工作流!
模型下载
1、Wan2_1-T2V-14B_fp8_e5m2.safetensors:
https://huggingface.co/Kijai/WanVideo_comfy/blob/main/Wan2_1-T2V-14B_fp8_e5m2.safetensors
📁 ComfyUI/models/diffusion_models
2、Wan21_T2V_14B_lightx2v_cfg_step_distill_lora_rank32.safetensors:
📁 ComfyUI/models/loras
3、Wan2_1-VACE_module_14B_fp8_e4m3fn.safetensors:
https://huggingface.co/Kijai/WanVideo_comfy/blob/main/Wan2_1-VACE_module_14B_fp8_e4m3fn.safetensors
📁 ComfyUI/models/diffusion_models
4、umt5-xxl-enc-bf16.safetensors:
https://huggingface.co/Kijai/WanVideo_comfy/blob/main/umt5-xxl-enc-bf16.safetensors
📁 ComfyUI/models/text_encoders
5、Wan2_1_VAE_bf16.safetensors:
https://huggingface.co/Kijai/WanVideo_comfy/blob/main/Wan2_1_VAE_bf16.safetensors
📁 ComfyUI/models/vae
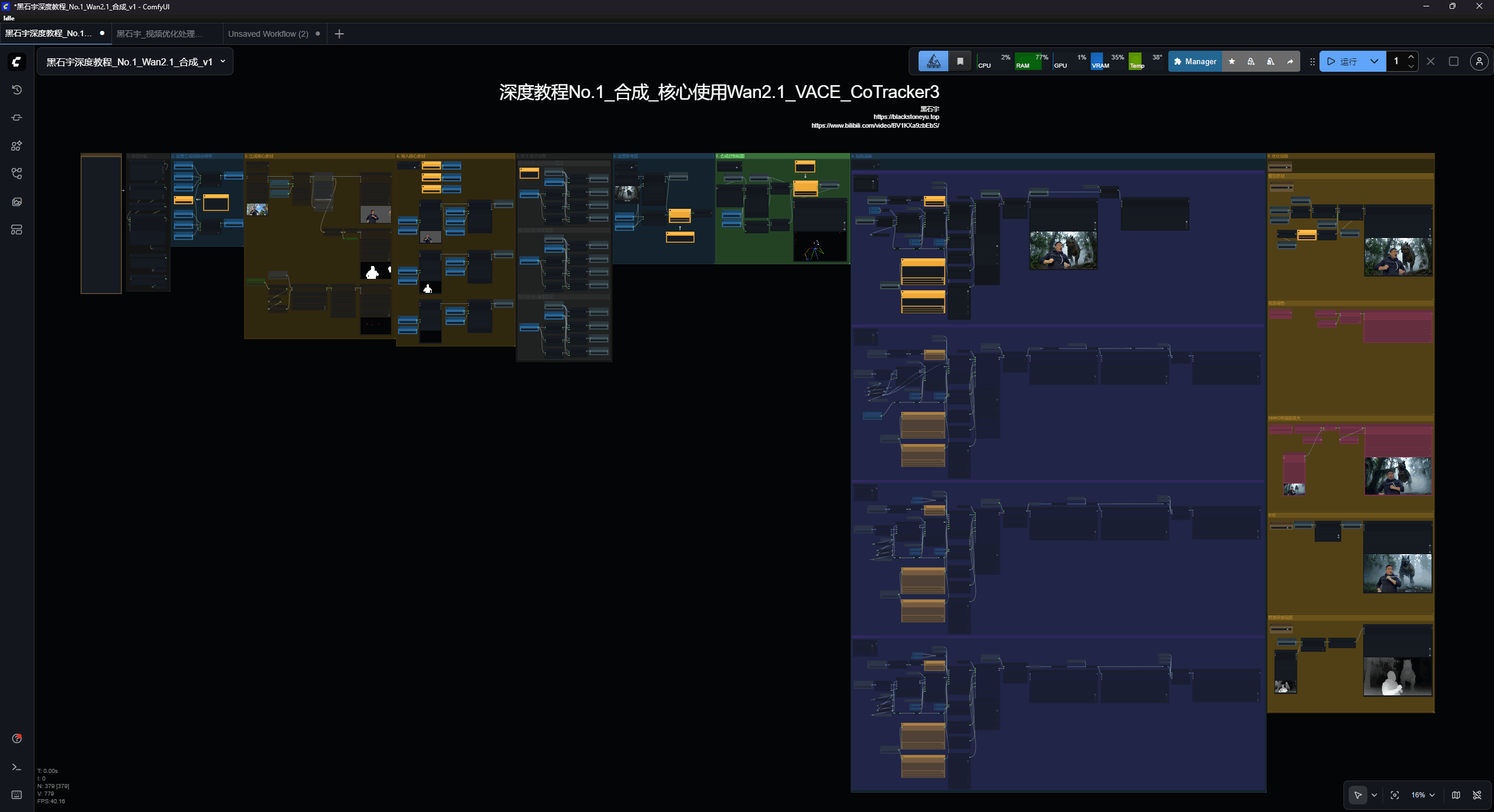
一、模型加载
第一步中选择对应的模型,不要选错!
此外,如果你是16或者12G以下的显存blocks_to_swap设置为40,新版本插件可以设置为48,如图!
vace_blocks_to_swap设置为15
这两个参数的值越大生成速度就越慢,但占用的显存会越低。
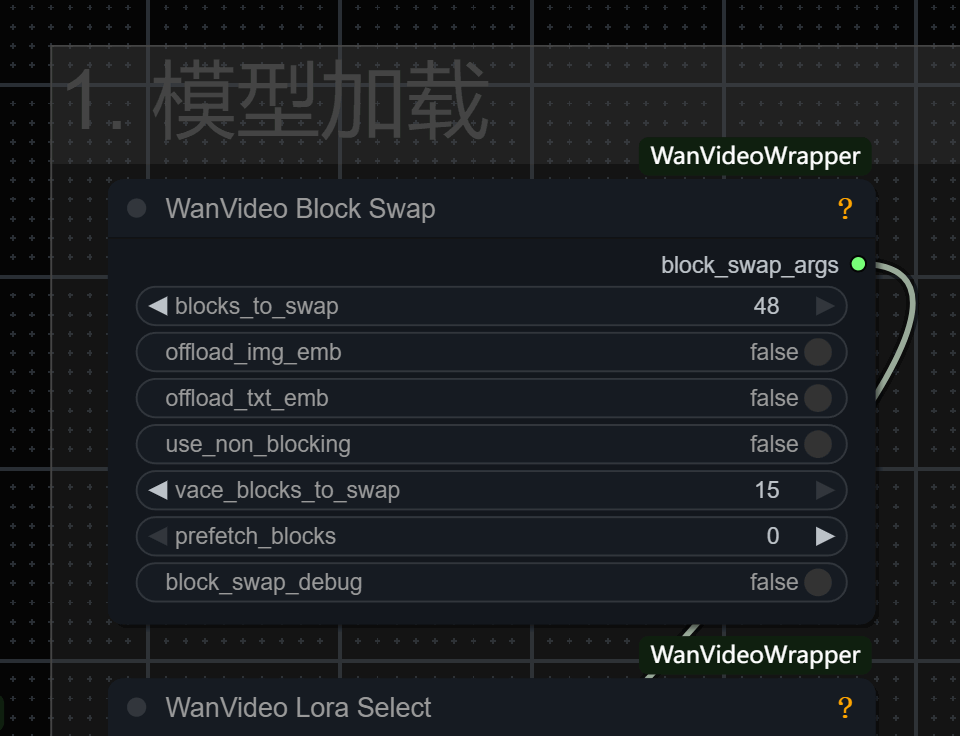
二、选择分辨率
工作流提供三种预设分辨率设置。
默认选择576p,因为它在质量、生成时间和出色的动画效果之间取得了良好的平衡。
16GB或以下最大支持到576P,8G显存建议选择3,也就是504p。
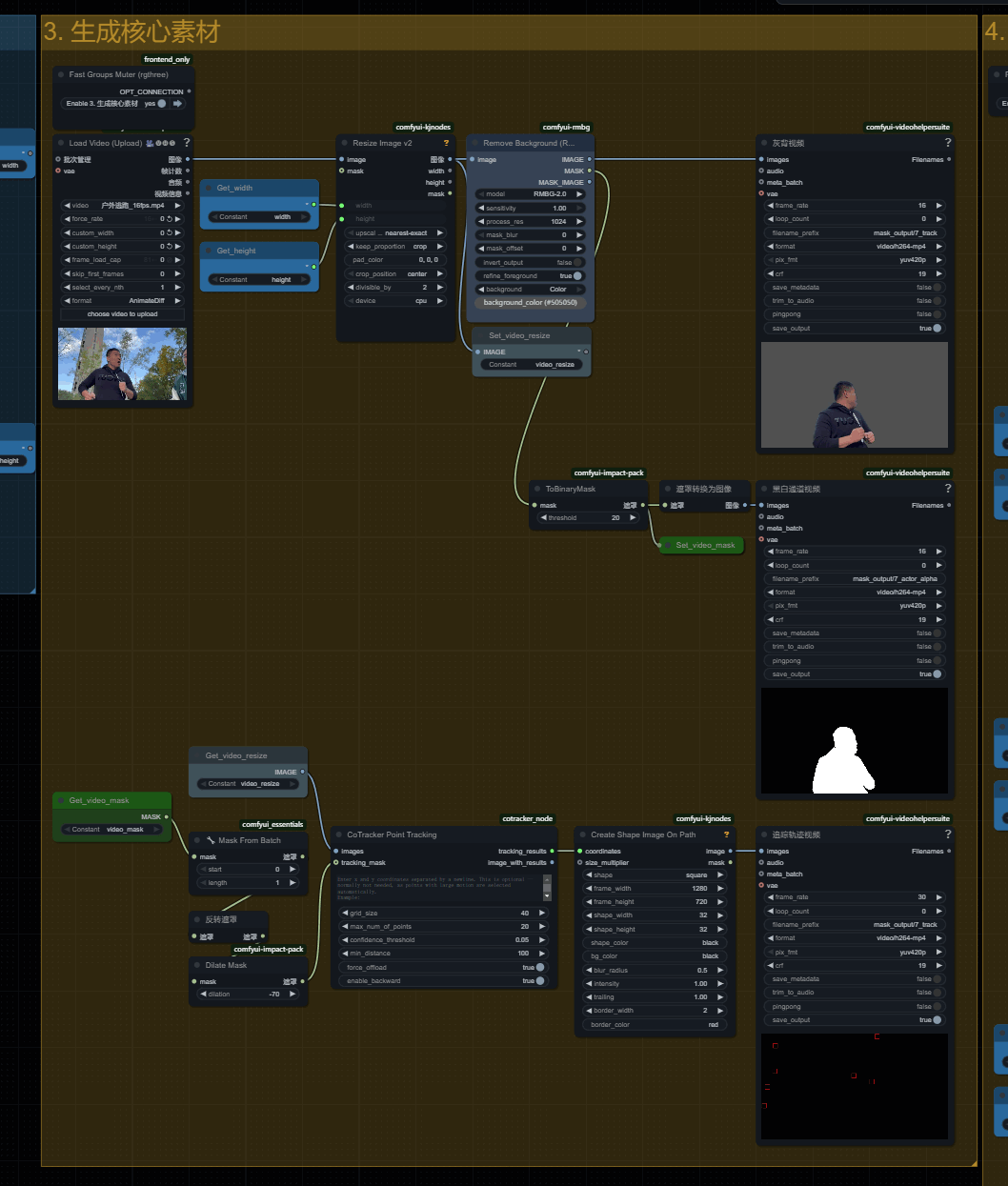
三、生成核心素材
在这一步中,可以将你实拍的素材,进行处理,生成vace模型所需要的三个参数!
灰色背景 + 主体 的视频
黑白通道视频 (主体是白色、背景黑色)
镜头运镜追踪视频 (红色边框的正方形就是追踪点)
(1和2两个视频是vace模型需要的参数,通过他们vace模型就会知道哪些区域需要进行重绘)
(3是给vace的控制图像参数,它可以让模型知道镜头的运动轨迹)
这就是我们创作需要的三个必要元素!
创建运镜轨迹我们使用了CoTraker节点
生成追踪点个数就是这个max num of points,这里值不是越大越好,
点太多会把模型的绘制空间锁住,自由度极低,还会出现不合理的运动。10~20之间是比较恰当的选择。
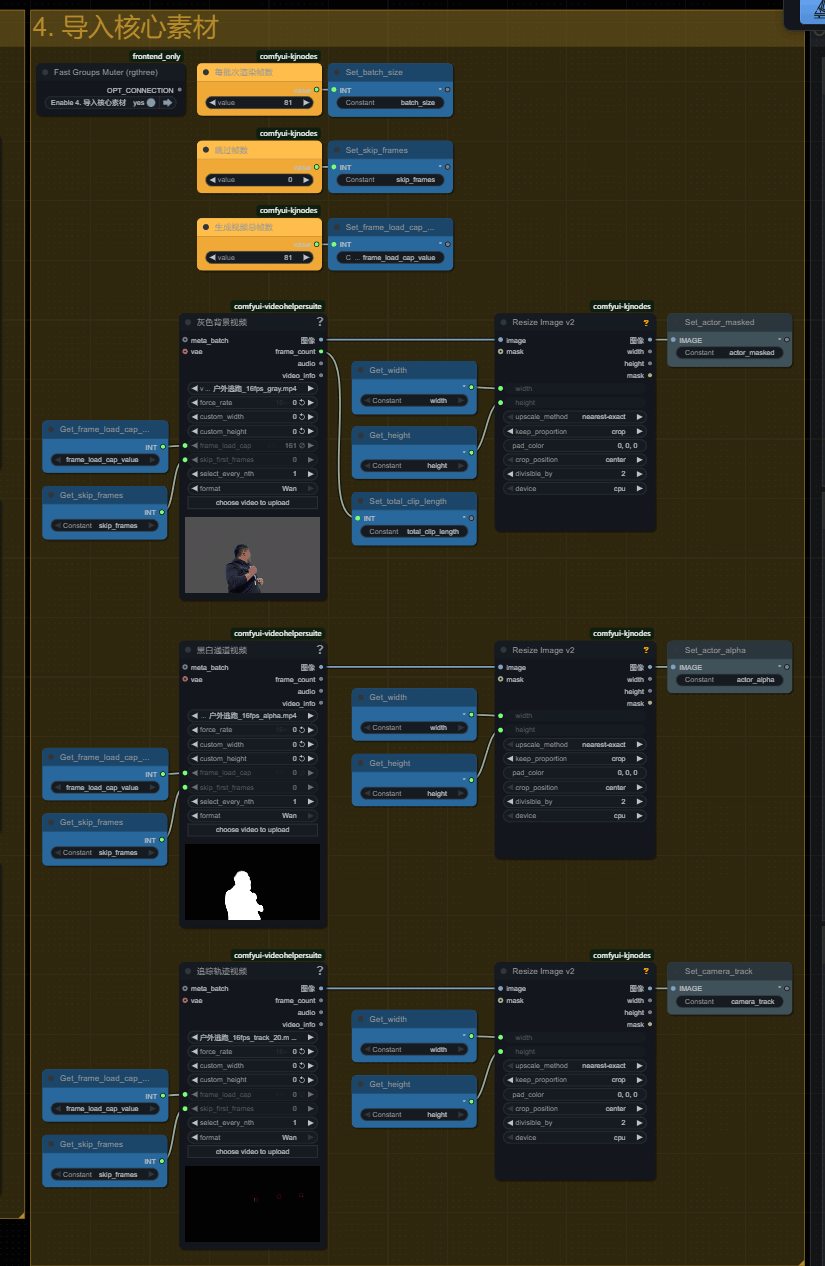
四、导入核心素材
将第三组生成的视频或者使用AE生成好的视频上传到对应的节点中,
我已经修改好了视频节点的标题,对应上传就好!
生成视频总帧数代表最大支持320帧!但先建议使用80帧,将整个工作流彻底掌握后再尝试多批次创作!
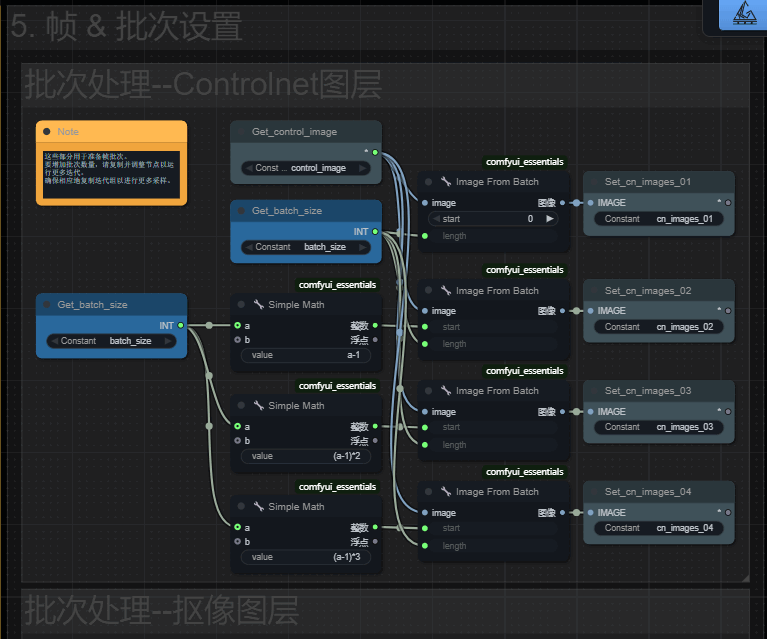
五、批次处理
第五组内容则是计算分割方式的!。
以cn_image为例, 01是取素材的前81帧!因为批次节点,start代表从哪一帧开始,下载的length参数代表截取的长度。
是我设置的是81,就是取素材的前81帧!
02就是在01后面再取81帧,但我们使用了上一批次的最后一帧作为起始帧,所以传给stat参数的值需要减1,后面以此类推。
理论上你可以生成无限时长,我这里用4组,你也可以复制粘贴这里,修改这里,让视频变得更长! 但我建议最长15秒也就是使用3组,太长的话结果会越来越偏离自己的预期!
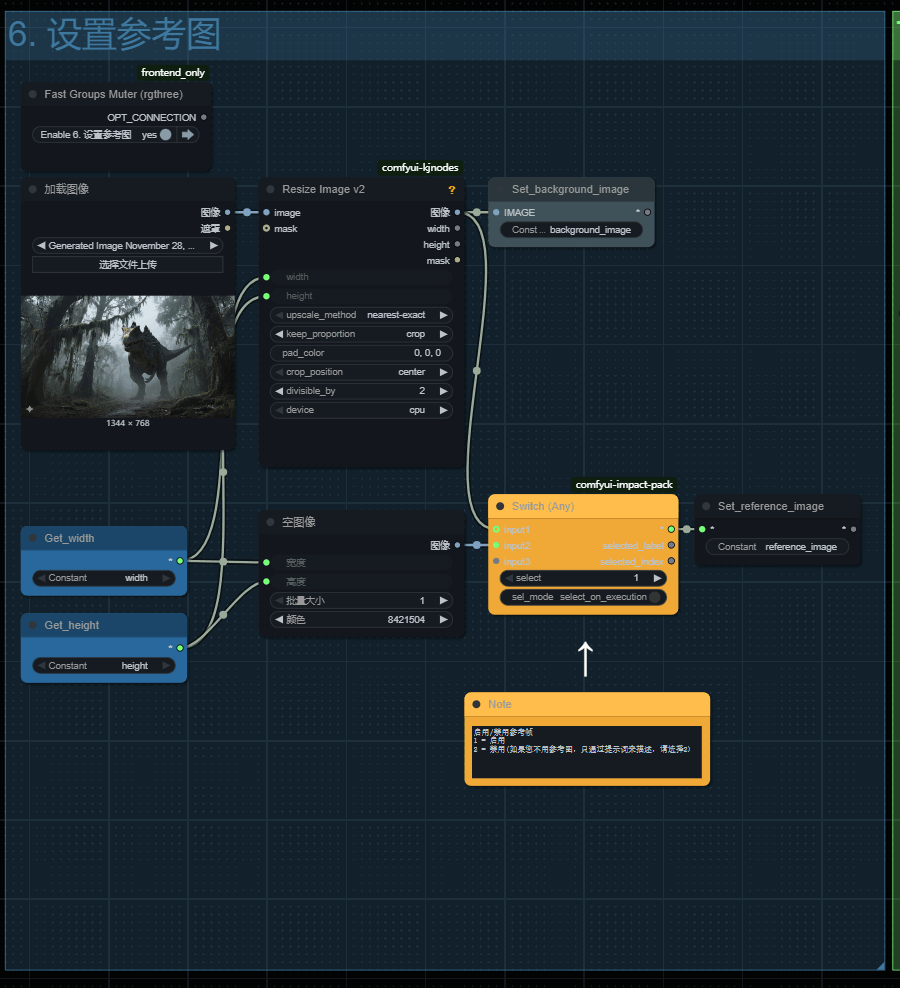
六、设置参考图
参考图这里比之前工作流多了一个切换节点
选择1,代表使用参考图作为生成视频的参数!
选择2,将会用一张纯灰色图片来当做背景图,代表仅仅根据提示词来生成背景!
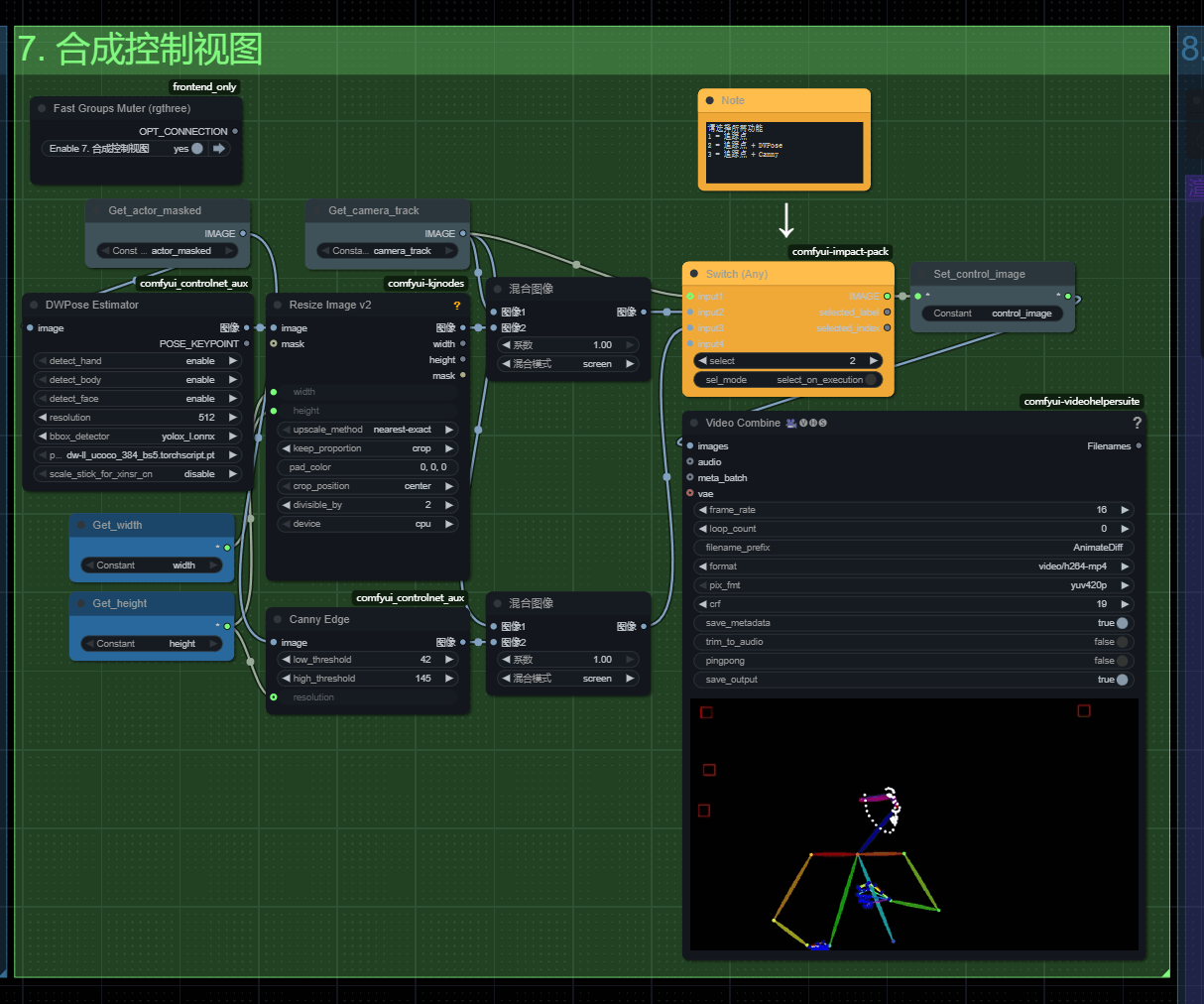
第七步部分-合成控制视图
将追踪视频 + openpose 或者 canny进行结合
选1:他就会老老实实只用镜头运镜追踪视频控制镜头
选2:把人物的 OpenPose也就是骨骼动作 + 运镜追踪进行融合
选3:就会将线稿 与 运镜进行融合,适用于部分室内场景。
如果镜头的主体是人物那么选择2,否则选择1.如果你的主体是室内,想保留室内结构,并且镜头没有人物那么选择3
点击运行,几秒钟后就可以看到openpose+追踪轨迹融合后的预览!
我们就是用它来控制视频的核心运动。
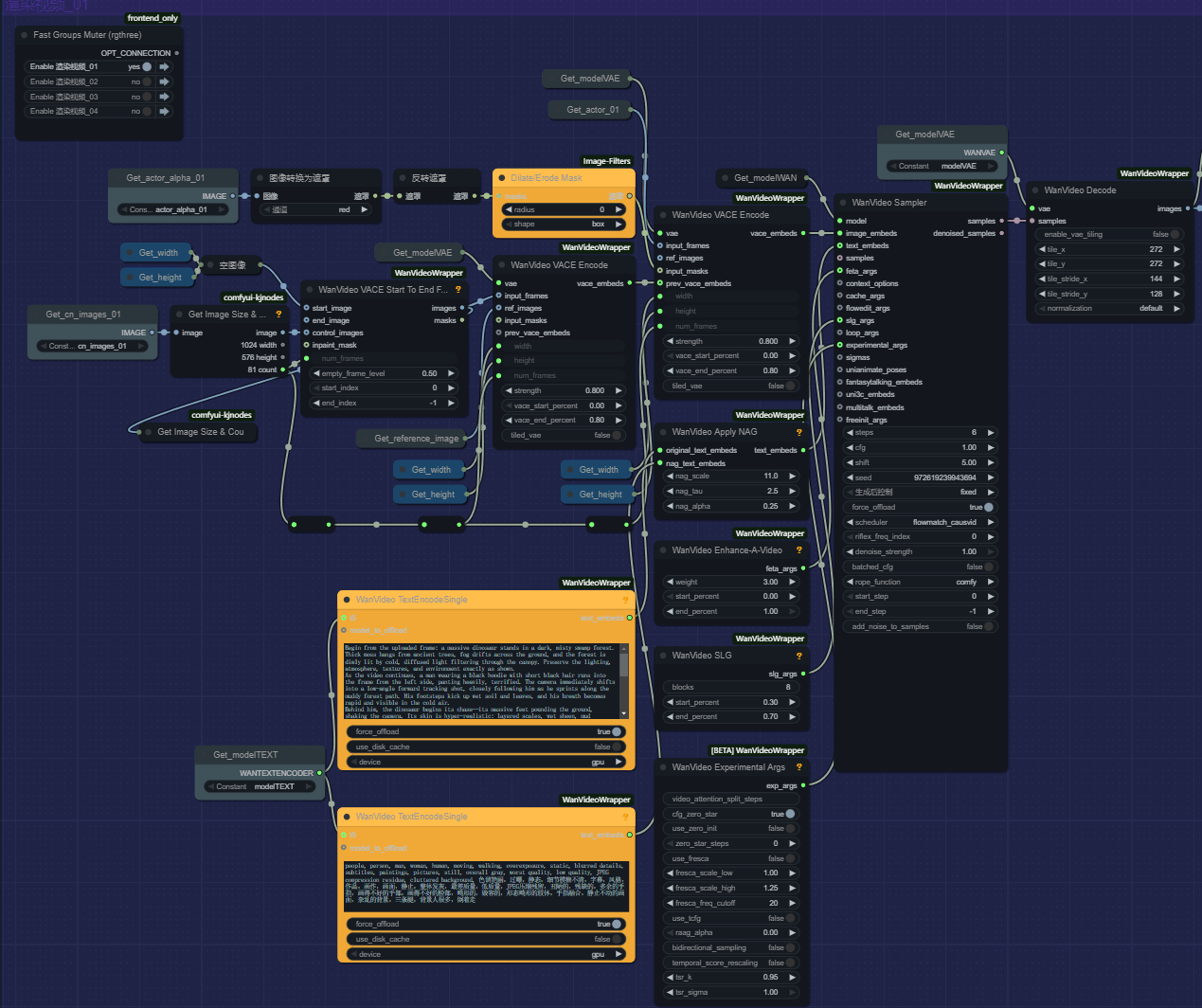
八、渲染生成视频
第一部分,下面其他部分略有不同,只使用一个批次的话,只开启渲染视频的第一组就可以了!
使用工作流的lora模型只需要6步就可以!步数太多会对实拍的内容有较大的影响!
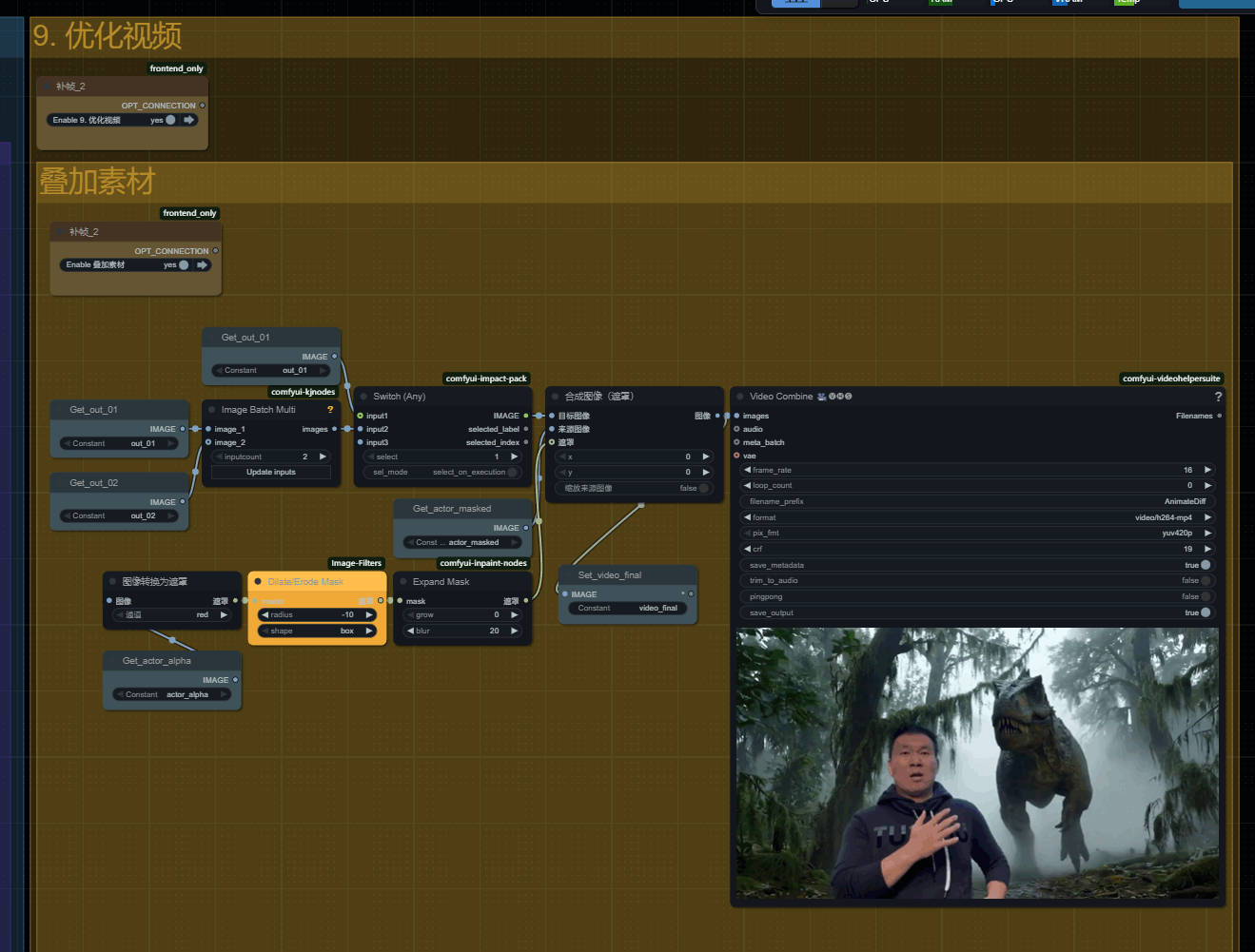
九、叠加素材
叠加素材这一组是拿出实拍素材的主体部分,通过遮罩向内收缩,并设置遮罩边缘模糊,然后从新覆盖到生成的视频上!
修复主体被破坏掉的问题。
如果你使用720P分辨率生成,并且素材为30fps,同时镜头晃动极低,那么生成的视频主体不会有较大变化的情况!
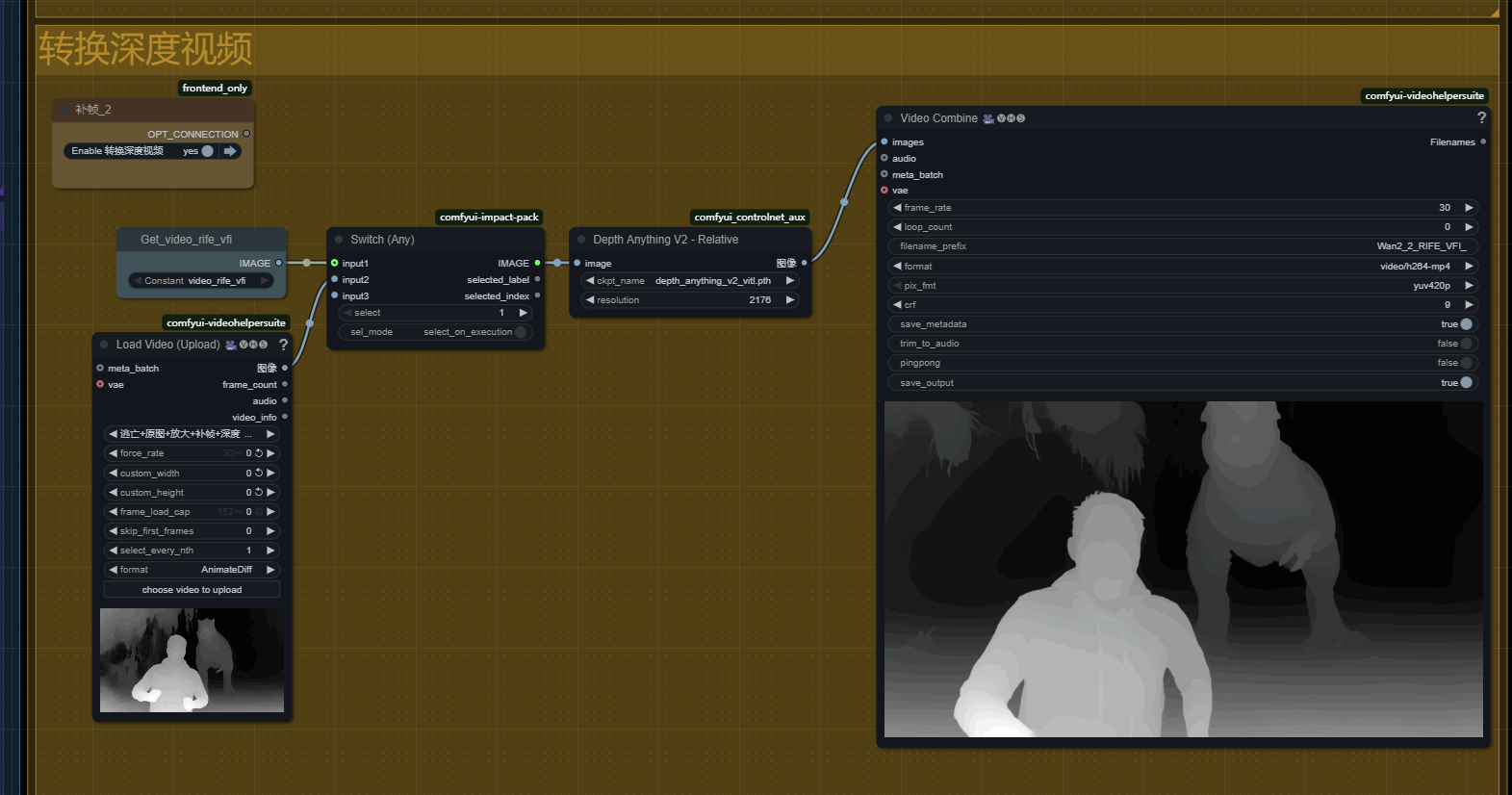
十、深度图视频
如果你想让你的视频更具有电影感,可以生成深度图视频,这样就可以通过Ae来设置视频的景深模糊!
好的效果需要不断打磨提示词和参考图!没有工作流是拿来一张图直接就出好效果的!
恐龙的效果,我差不多微调了有50次提示词,最终才得到比较中意的效果。大家需要有一定的耐心才能得到好的效果!
更希望大家能学到创作的思路!
资源下载
如果你喜欢我的教程,还请在点赞订阅我的B站和油管频道,让我更有动力努力下去,也希望你留下宝贵建议,谢谢!


工作流文件:黑石宇深度教程_No.1_Wan2.1_合成_v1.json.zip
素材文件:参考图.zip
景深模糊插件:AE景深模糊插件.zip