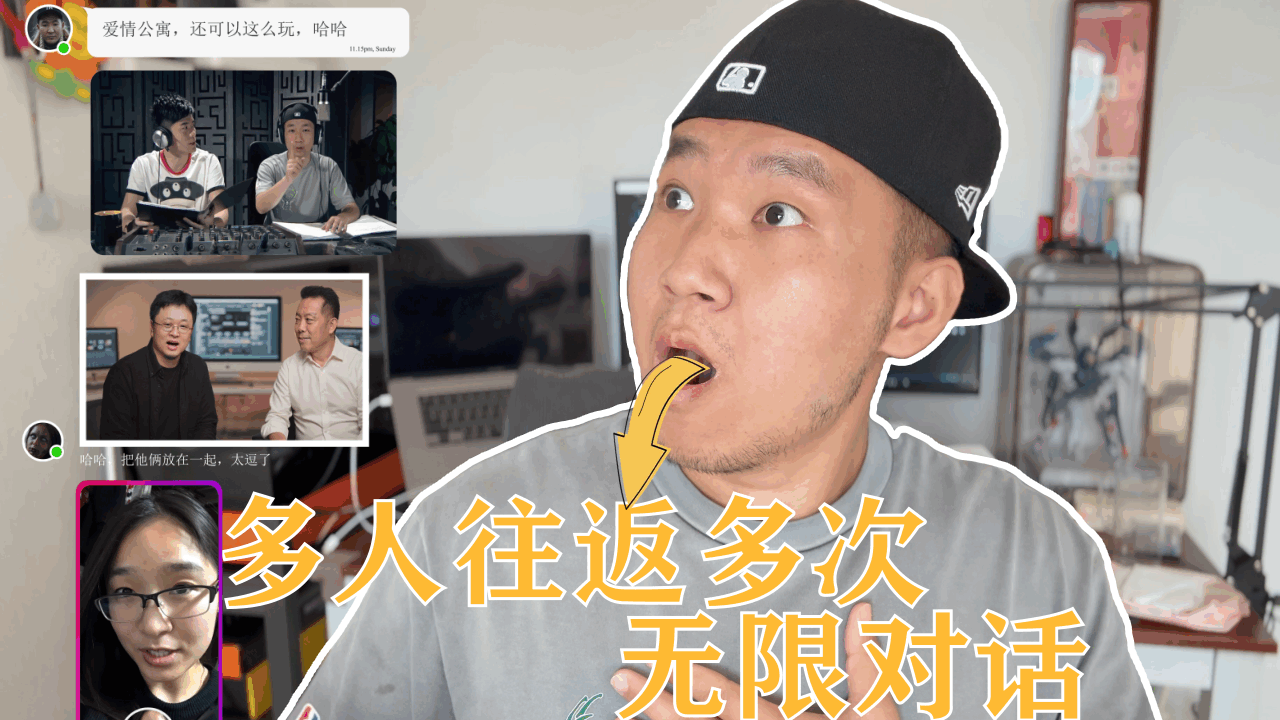
多人往返无限对话,音频制作技巧,免费创作真实且生动的多人互动视频
Hello同学们,这里是黑石宇老师的频道,近期我总刷到付费制作的对话短视频!
经过仔细的研究我将多种生成方式魔改到一个工作流中,并且做了简化。
视频B站链接: https://www.bilibili.com/video/BV1KXa9zbEbS/
视频油管链接(需梯子):https://youtu.be/vst2_CCaUK8
我将多人无限对话分为两种方式,分别是切换镜头和一镜到底。
通过3个机位对应的镜头,使用每一段音频分别生成视频



两段音频
将两个人的音频各剪切为三部分,用对应的镜头进行视频生成,最总合成到一起。
一镜到底的多人对话同样需要两个音频,但只需要单张图片即可!
已经到底的单人对话,则只需要一个音频,一张图片即可!

一、模型下载安装
此工作流程中使用的模型和节点
运行工作流之前,请确保下载所有必需的模型并安装自定义节点。
🟫 WanVideo Model Loader
下载 wan2.1-i2v-14b-480p-Q4_0.gguf [点击]
或下载 其他 Q 版本 这取决于你的显卡显存 [点击]
存储路径📂 ComfyUI/ models/diffusion_models/
🟫 WanVideo Lora Select
下载lightx2v_I2V_14B_480p_cfg_step_distill_rank64_bf16.safetensors** [点击]
更多版本 Loras [点击]
存储路径📂 ComfyUI/models/loras/
🟫 Multi/InfiniteTalk Model Loader
下载Wan2_1-InfiniteTalk_Single_Q8.gguf [点击]
下载Wan2_1-InfiniteTalk_Multi_Q8.gguf [点击]
获取从这里获取更小的 Q 版本 [点击]
存储路径📂 ComfyUI/models/diffusion_models/
🟫 Load VAE
下载 wan_2.1_vae.safetensors from [点击]
存储路径📂 ComfyUI/models/vae/
🟫 Load CLIP Vision
下载 clip_vision_h.safetensors [点击]
存储路径📂 ComfyUI/models/clip_vision/
🟫 Wav2vec2 Model Loader
下载 wav2vec2-chinese-base_fp16.safetensors [点击]()
存储路径,如果没有wav2vec2文件夹,需要自己手动创建📂 ComfyUI/models/wav2vec2/
🟫 WanVideo TextEncode Cached
下载 umt5-xxl-enc-bf16 [点击]
存储路径📂 ComfyUI/models/clip/
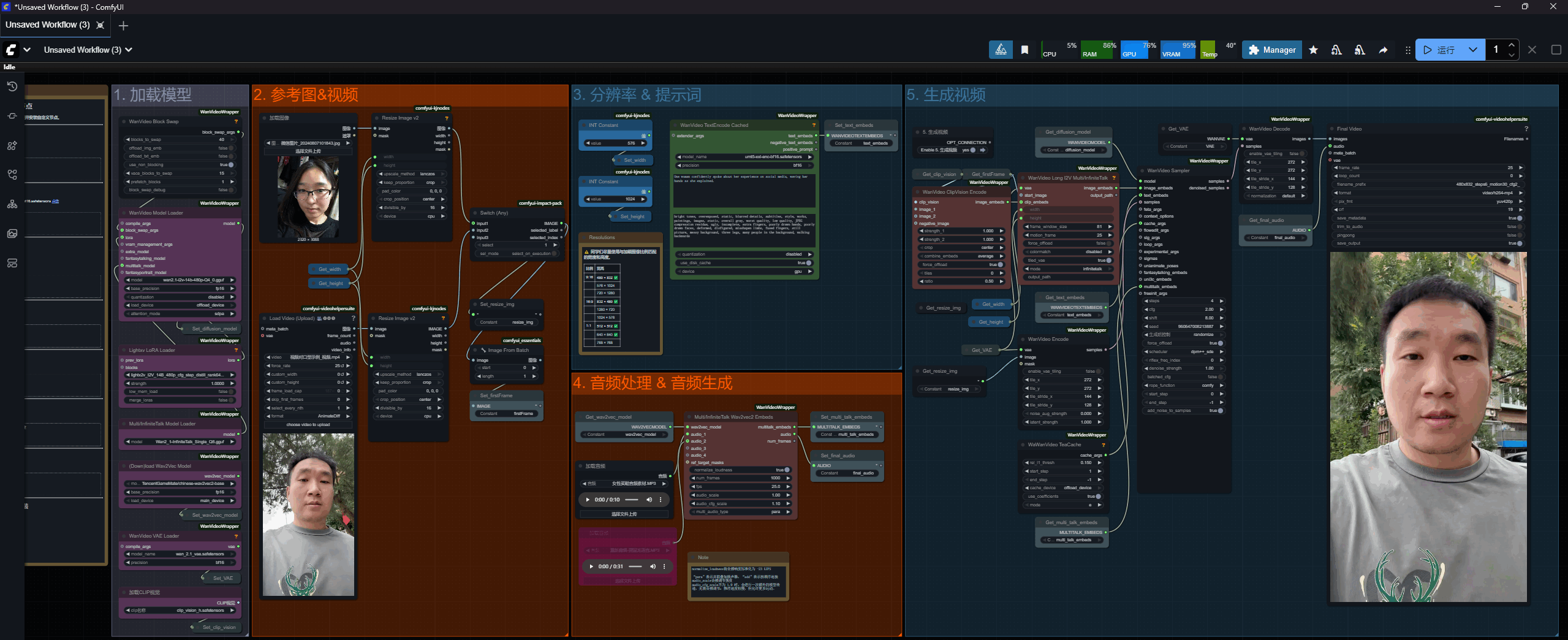
二 、 工作流一共分为五个部分
从左只有工作流一共分为五个部分,左侧的笔记节点中,有运行当前工作流所需的所有模型信息,你可以选择和我使用相同的模型,也可以选择其他适合你当前显存的模型!下载好后,一定要存储到对应的目录下!并在第一步模型选择中选择正确的模型!
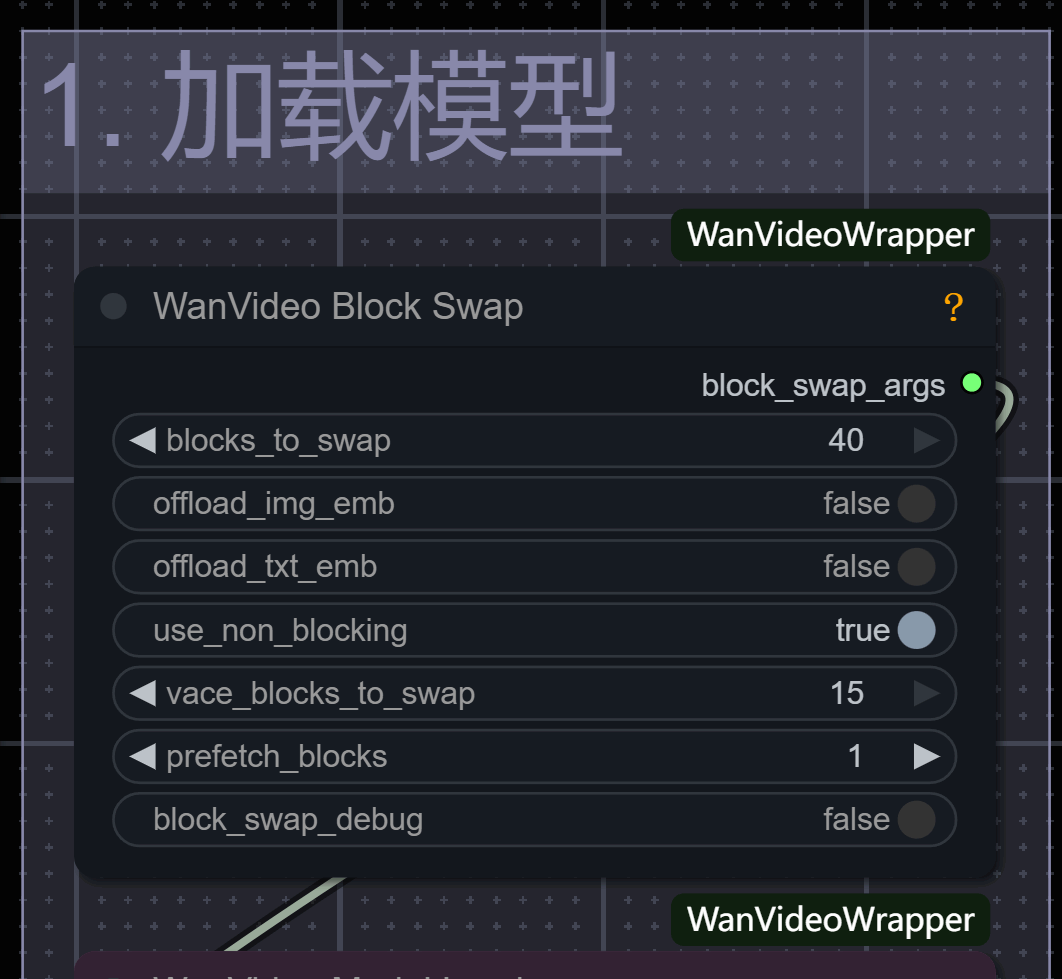
第一步中的Block Swap节点,前几期教程中我们也一直在用它。它是一个针对视频模型实现显存优化的工具节点!他可以让你在不需要使用时,将模型的部分模块从GPU挪到CPU,并在需要时重新加载。如果你学过编程,那么它就相当于懒加载,用闲置CPU存储,GPU需要使用时直接去拿过来用。省去了很多计算步骤。这样可以降低峰值显存占用,是大模型能够在显存较小的GPU也就是显卡上运行!
但由于数据需要在CPU和GPU之间传输,这会让生成视频的推理过程变慢。所以Blocks to Swap参数代表GPU和CPU之间“块交换数量”。范围是0~40,数值越高,显存占用越低,但运行速度也会变慢;如果是0,代表不交换,则节点无用。
use_non_blocking 非阻塞性传输方式,开启它后不仅可以节省内存,传输速度也会更快!
prefetch_blocks 预先取的块数,它可以加快处理速度,但会增加内存占用。如果你的设备支持设置为1即可平衡内存和速度!
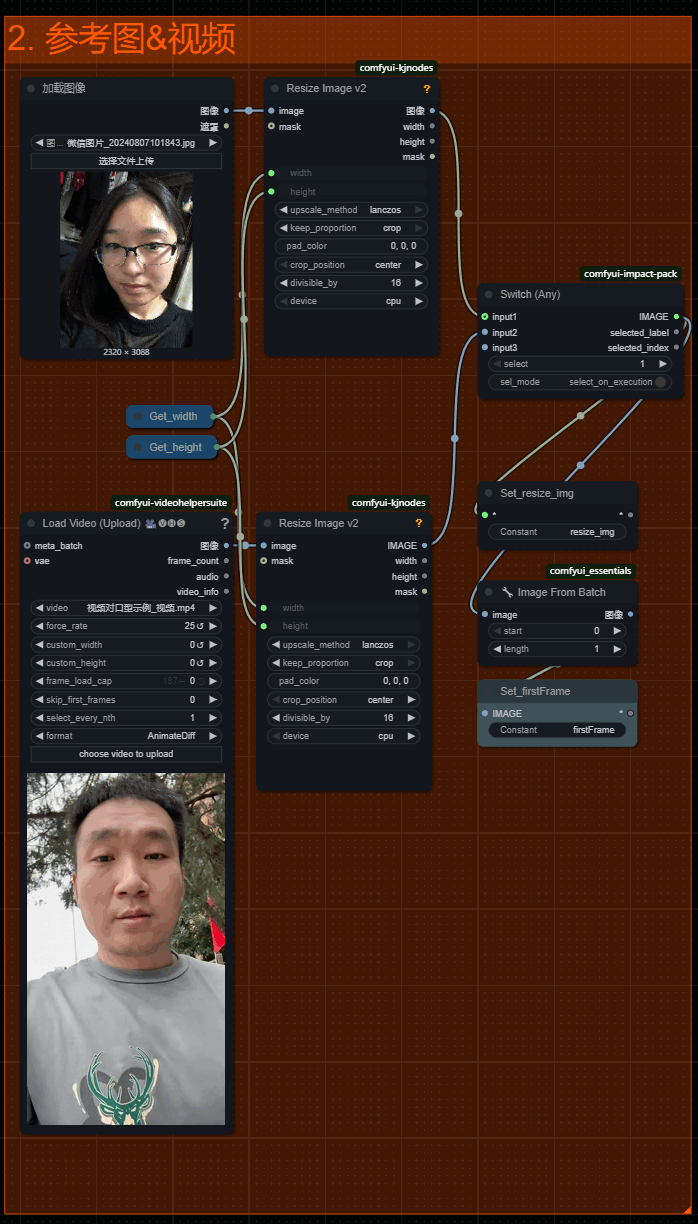
三、 参考图 & 视频
工作流支持通过单张图片 (单人&双人)以及视频生成对话视频!选择图片生成在第二部中右侧Switch节点中选择来源1,通过视频生成选择来源2!
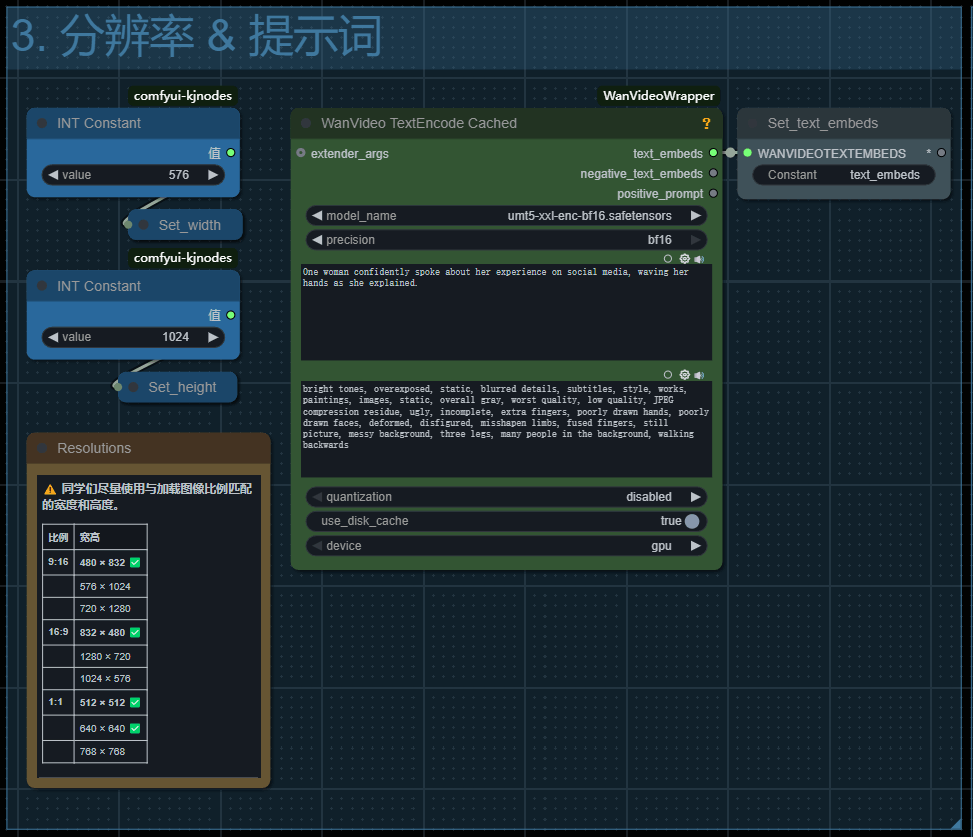
四、提示词
单人的提示词最就简单可以使用
A man is talking. 或 A woman is talking.
复杂一些,添加手部动作可以这样写
One woman confidently spoke about her experience on social media, waving her hands as she explained.
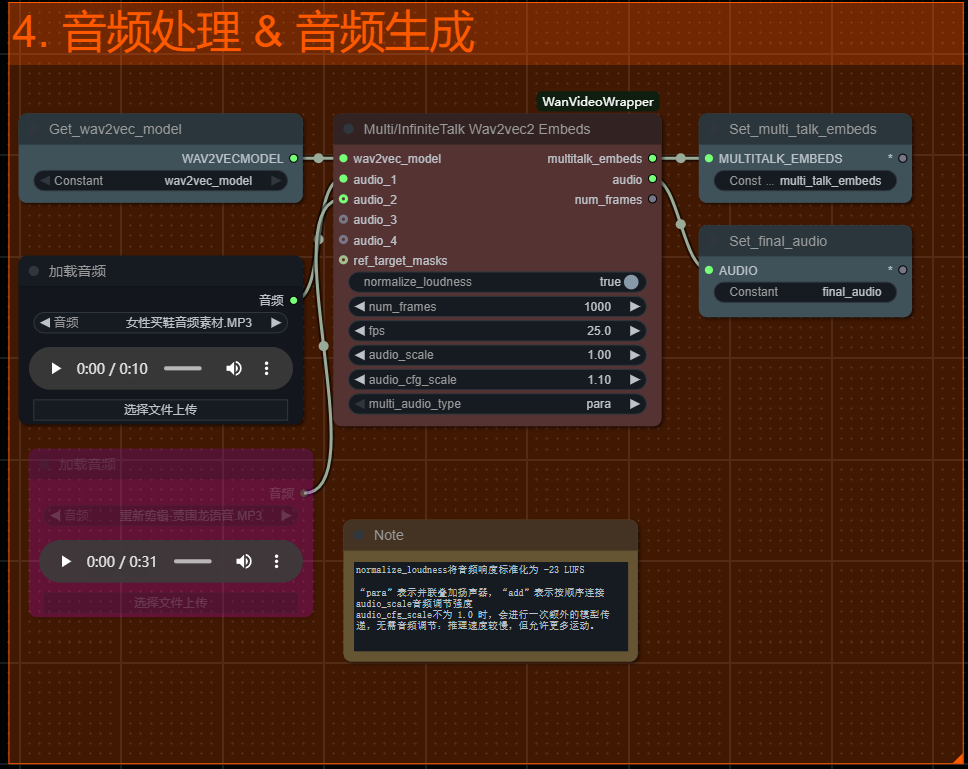
六、 音频
multi_audio_type参数有两个选项:para & add
para 代表设置的音频将同时播放,对应视频中的人物也会一起完成口型动作。
add 代表设置的音频逐个播放,对应视频中的人物会从左至右完成口型动作。
七、渲染
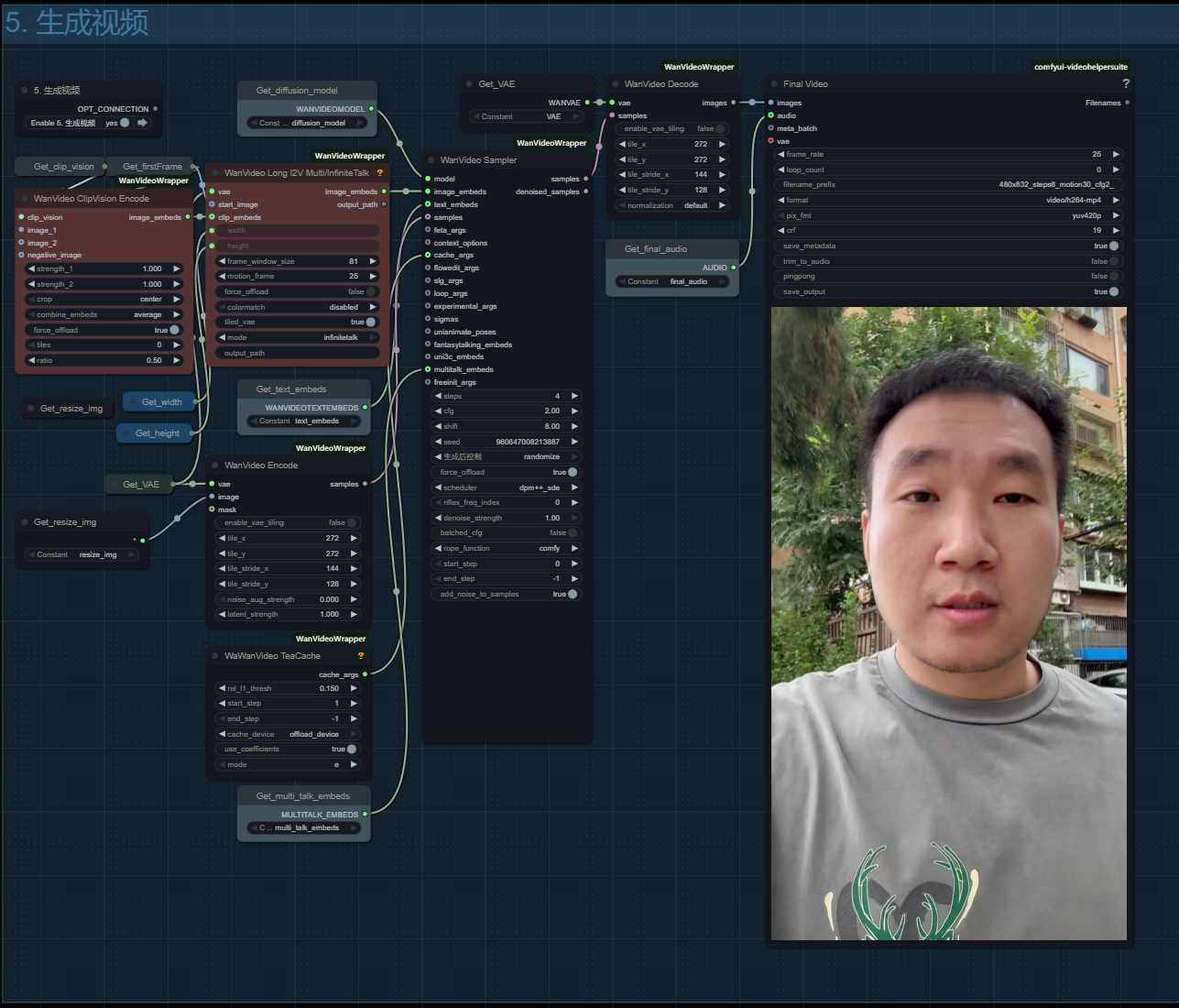
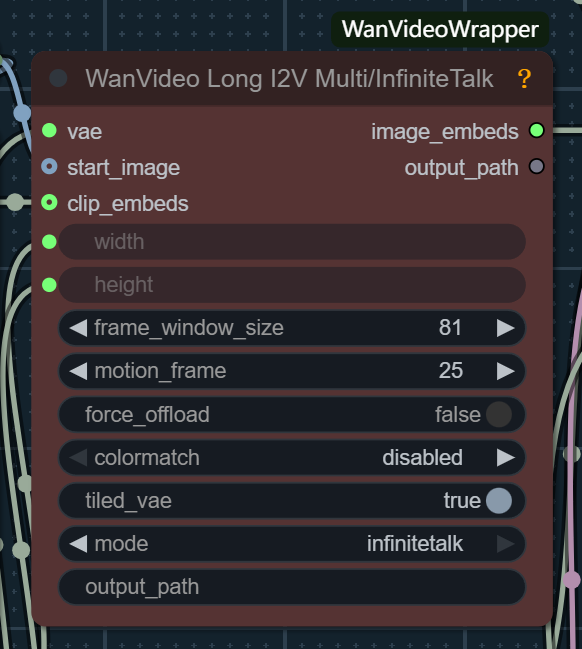
这里frame_window_size帧窗口大小,代表每个处理块中的帧数,我设置为 81。
同学们可以理解为将每81帧生成一个视频,最后再合并成一个完整的视频!
比如你要生成总帧数为200帧的视频,那么它会将200帧分为三个处理块!也就是生成三个视频,视频分别为81帧81帧和38帧!
数值越大每个视频之间的过度就越平顺,唇性同步的一致性也就越高,但会占用更多的显存。
montion_frame是控制每个视频之间的重叠帧数,以保证视频之间能有更好的衔接,通常设置为帧窗口的10%~30%.较高的值可以带来更稳定的过度效果,但也会降
低处理速度。
这两个参数大家根据实际显存以及生成视频的长度来对应调整!
着色再上一期我详细的讲解了
mode参数对应的选项中多对话选项指的是旧版本的多对话模型。无论你使用的是单语音还是多语音模型都是无限对话模型,所以这里选择无限对话模型不需要修改!
工作流 + 素材下载
如果你喜欢我的教程,还请在点赞订阅我的B站或油管频道,让我更有动力努力下去,也希望你留下宝贵建议,谢谢!


工作流 : 黑石宇_Wan_infinitetalk.zip
测试素材:第六期分享素材.zip