一站式视频创作工作流,镜头控制,视频+音频+换脸同步创作
因为前段时间重看了指环王!
最后人族举起长剑挥舞斩向半兽人的镜头太帅了!久久不能自已!
于是做了这个短片,感谢我的好朋友金阳同学被自愿成为我的短片主角!我服务器的带宽不高可能得等一会!
B站链接:https://www.bilibili.com/video/BV1tZbtzEEDw/
油管链接:https://youtu.be/7X9ZTFx5PhE
↓↓↓ 工作流和素材文件在文章最下方 ↓↓↓
友情提示! 视频里忘记说了!
lora在镜头高速移动的时候处理效果不好!
如狗狗急速奔跑等等,高速移动画面请关闭lora,采样器修改为euler,调度器simple ,总步数设置为20,前10后10, cfg设置为3.5!效果会更好一些!
每一个好的镜头都需要不断的调整提示词,总部署,是否开启lora等等!需要不断的打磨!
短片我一共生成了800多个5~8秒的镜头,实在没有时间剪辑更多内容!
有时一个好的镜头可能就需要调试一整天的时间!希望大家能真正喜欢上生成式Ai将它玩起来!不要用几次就放弃!
如果你的英语不好,建议大家使用Grok3或者Deepseek进行提示词翻译,同样的画面你的描述翻译过来和真正英语描述是有很大出入的,因为这一点我浪费了很多时间! 并且不要拆分翻译,将完整的一句话一起翻译,不要将提示词拆分开来进行翻译!
比如
在一侧并排跟拍镜头 谷歌翻译 Tracking shot from one side
在一侧并排跟拍镜头 百度翻译 Side-by-side following shot
实测生效的提示词为 camera traking alongside
Grok
grok.com 每天的免费次数足够了!希望大家不要再这上面党务时间!
希望大家也可以通过照片生成有趣好玩的内容!
提示词
The camera gradually moves away from the man and rises high into the air。The man stood motionless on the sidewalk, looking at the camera.In the background,parked cars, flashing traffic lights, pedestrians crossing the road.
素材

预览

The camera gradually moves away from the man and rises high into the air。The man stood motionless on the sidewalk, looking at the camera.In the background,parked cars, flashing traffic lights, pedestrians crossing the road.


模型下载
WAN 2.2 模型:
safetensors(24G显存下载fp16,fp8不如ggufQ8): Comfy-Org/Wan_2.2_ComfyUI_Repackaged at main
5B GGUF(4G显存可以跑,但不推荐,效果超级差!): QuantStack/Wan2.2-TI2V-5B-GGUF at main
14B Text-to-Video GGUF(推荐): QuantStack/Wan2.2-T2V-A14B-GGUF at main
14B Image-to-Video GGUF(推荐): QuantStack/Wan2.2-I2V-A14B-GGUF at main
Text Encoders:
umt5 GGUF: city96/umt5-xxl-encoder-gguf at main
umt5 safetensors: https://huggingface.co/Comfy-Org/Wan_2.2_ComfyUI_Repackaged/resolve/main/split_files/text_encoders/umt5_xxl_fp8_e4m3fn_scaled.safetensors
Loras:
LightX_2V Lora: Kijai/WanVideo_comfy at main
MM-Audio 模型和节点Github:工作流中笔记节点有更详细的说明!
MM-Audio Models: Kijai/MMAudio_safetensors at main
ComfyUI-MMAudio Node (GitHub): GitHub - kijai/ComfyUI-MMAudio
工作流
工作流一共分为三大部分,工具组 ,视频生成组, 音频生成组

工具组
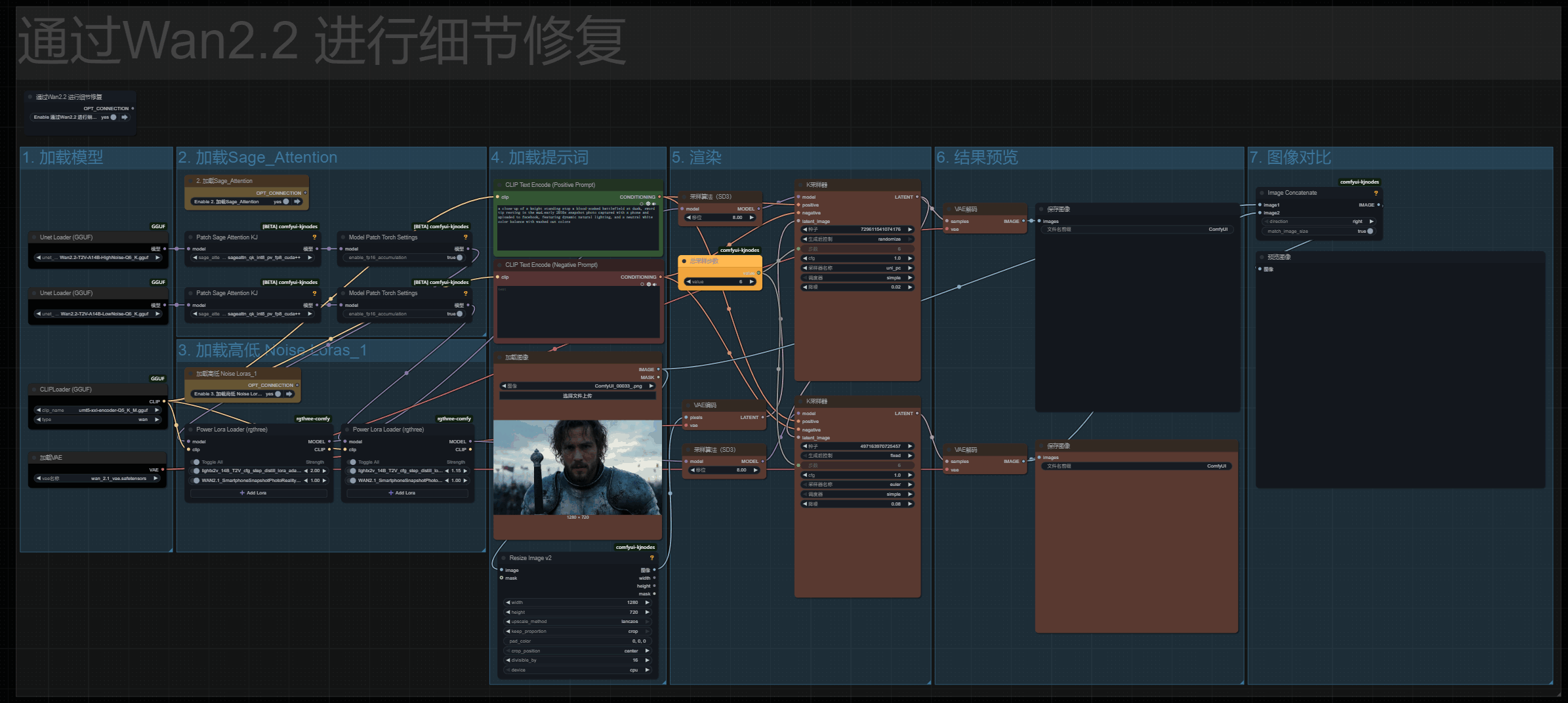
包含洗图和面部替换,面部替换对之前教程的工作流进行了优化,并添加了redux模型!
不喜欢或者不用的话可以直接将工具组删除。我再视频中也描述了工具组如何和视频生成进行配合!
视频生成
视频生成分为三个流程! 文生视频、图生视频、首尾帧视频!
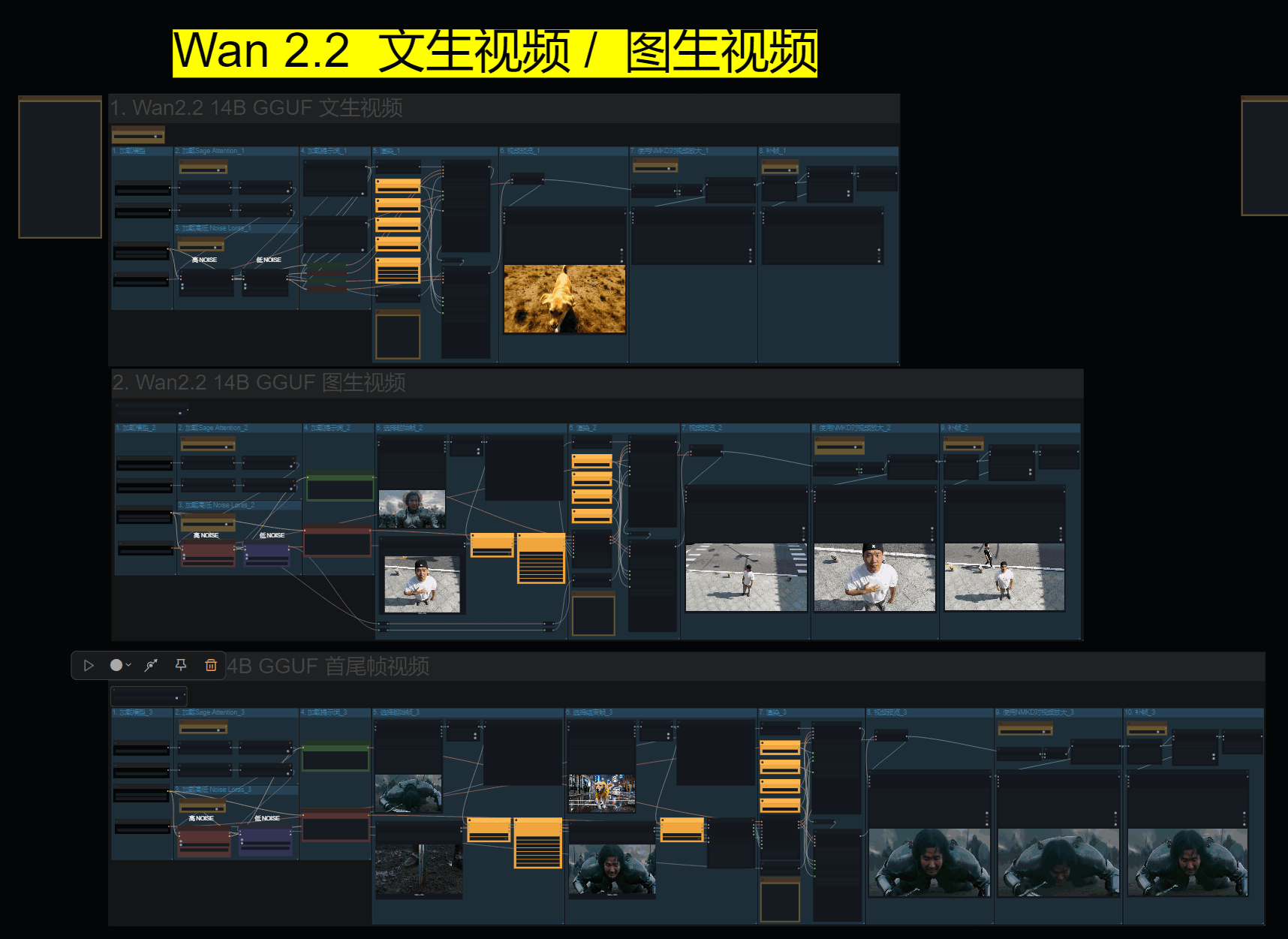
以文生视频举例!最左侧是模型加载,第二部和第三步对应是加载Sage和lora,Sage的安装方式在博客的最下方!Sage安装复杂目录环境不好维护,不推荐!
Lora的高低噪可以设置不同的强度!高噪模型强度高视频运动幅度会大一些!可以高3低1!或者高2.5低1.5,根据实际情况来调整即可!
通常来说高低都为2是一个不错的设置!
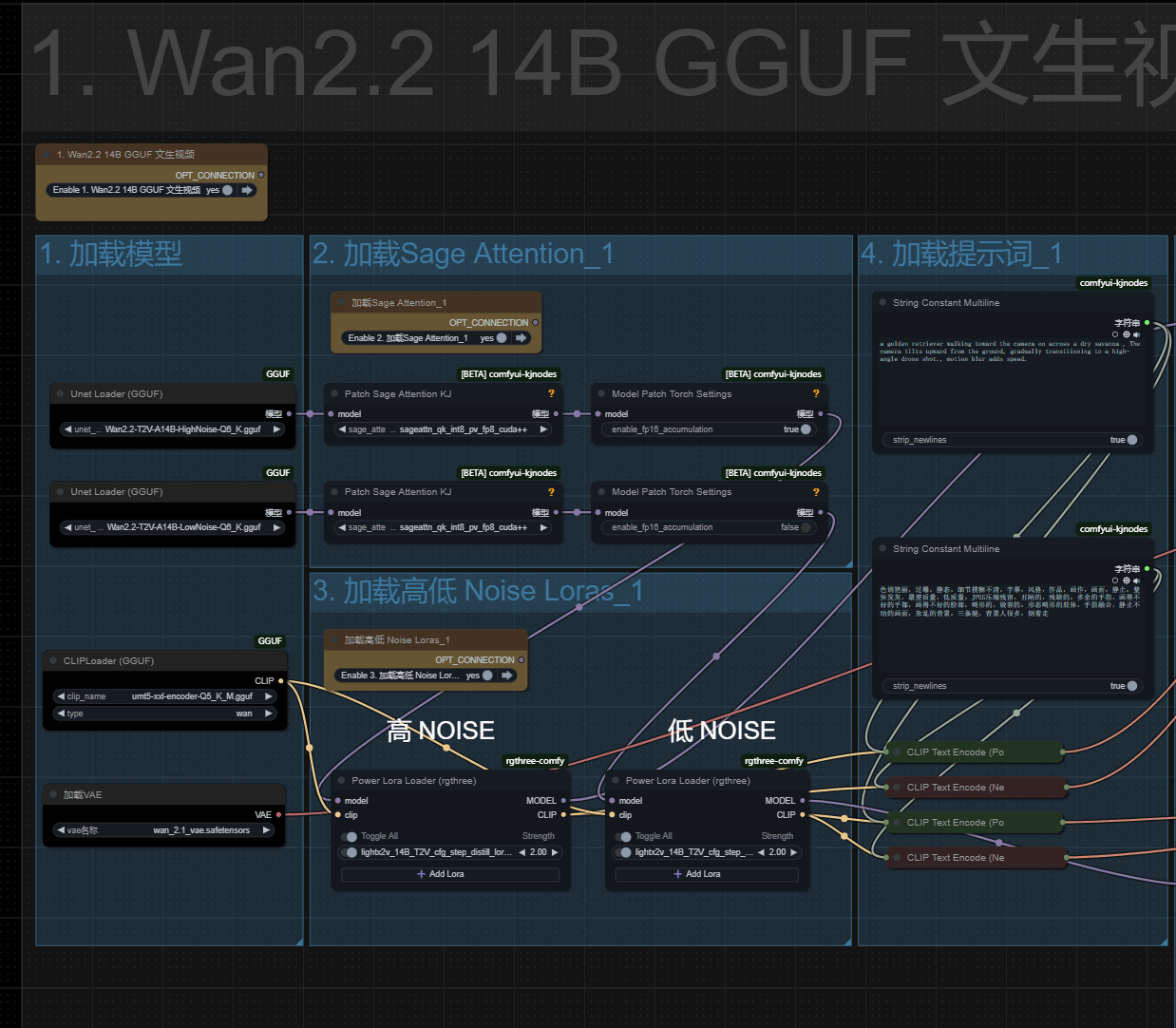
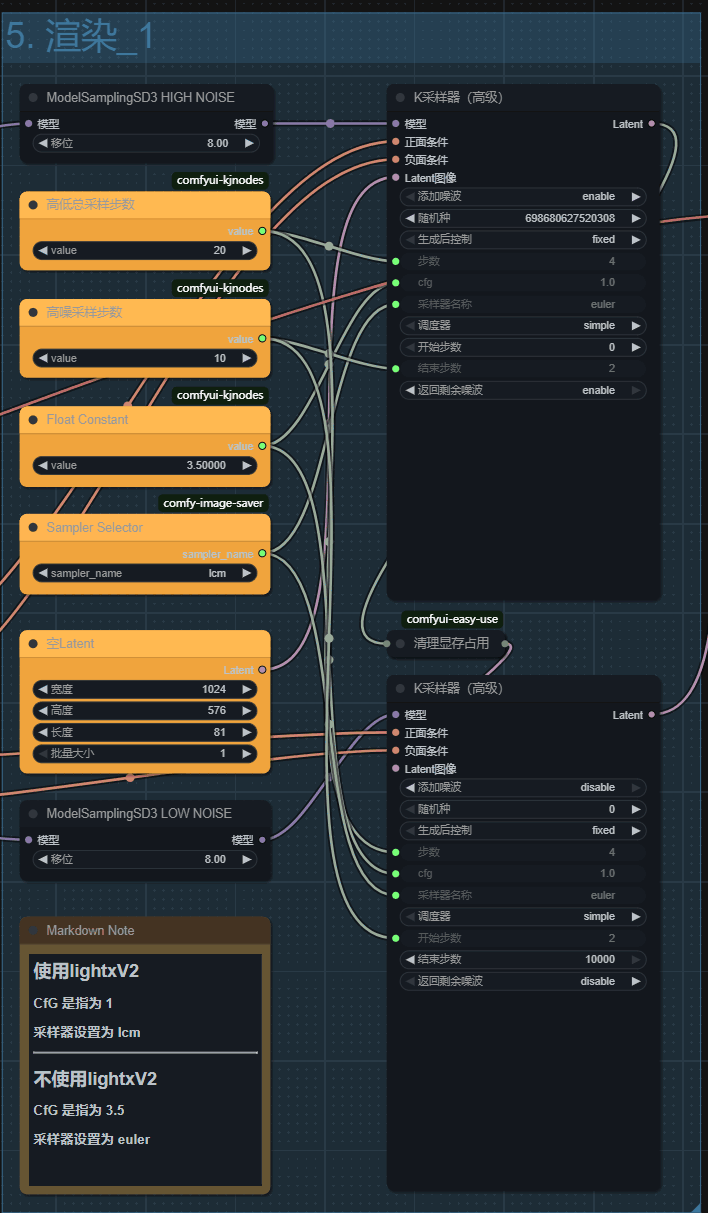
采样
如果使用了加速Lora
那么总步数可以设置最小为4,高低各为2即可!
采样器需要设置为lcm
cfg设置为1
不使用lora
那么总步数需要设置为20,高低各为10!
采样器需要设置为eular
cfg设置为3.5
分辨率看设置情况!16G以内建议576P 或 504p, 我的设备16G显存使用加速lora文生视频720p的话,大概要20分钟左右!
1 = 720p (1280 x 720)
2 = 576p (1024 x 576)
3 = 504p (896 x 504)
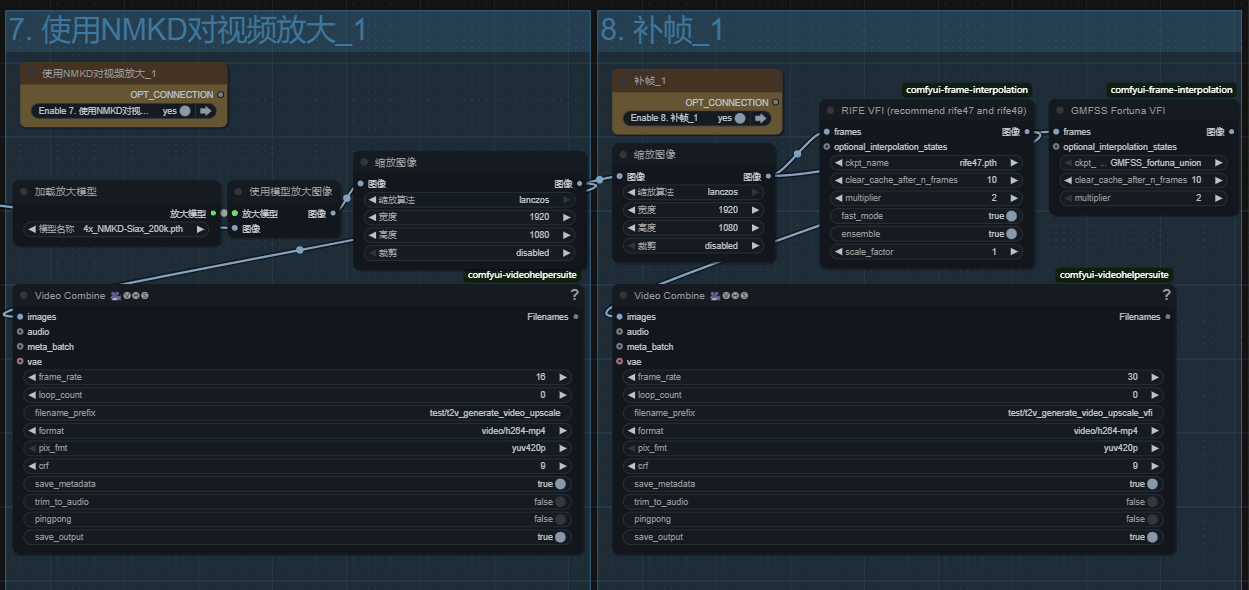
视频放大以及补帧!
放大使用的nmkd模型!之前在面部替换工作流中讲解过!效果相当不错!补帧就不解释了!
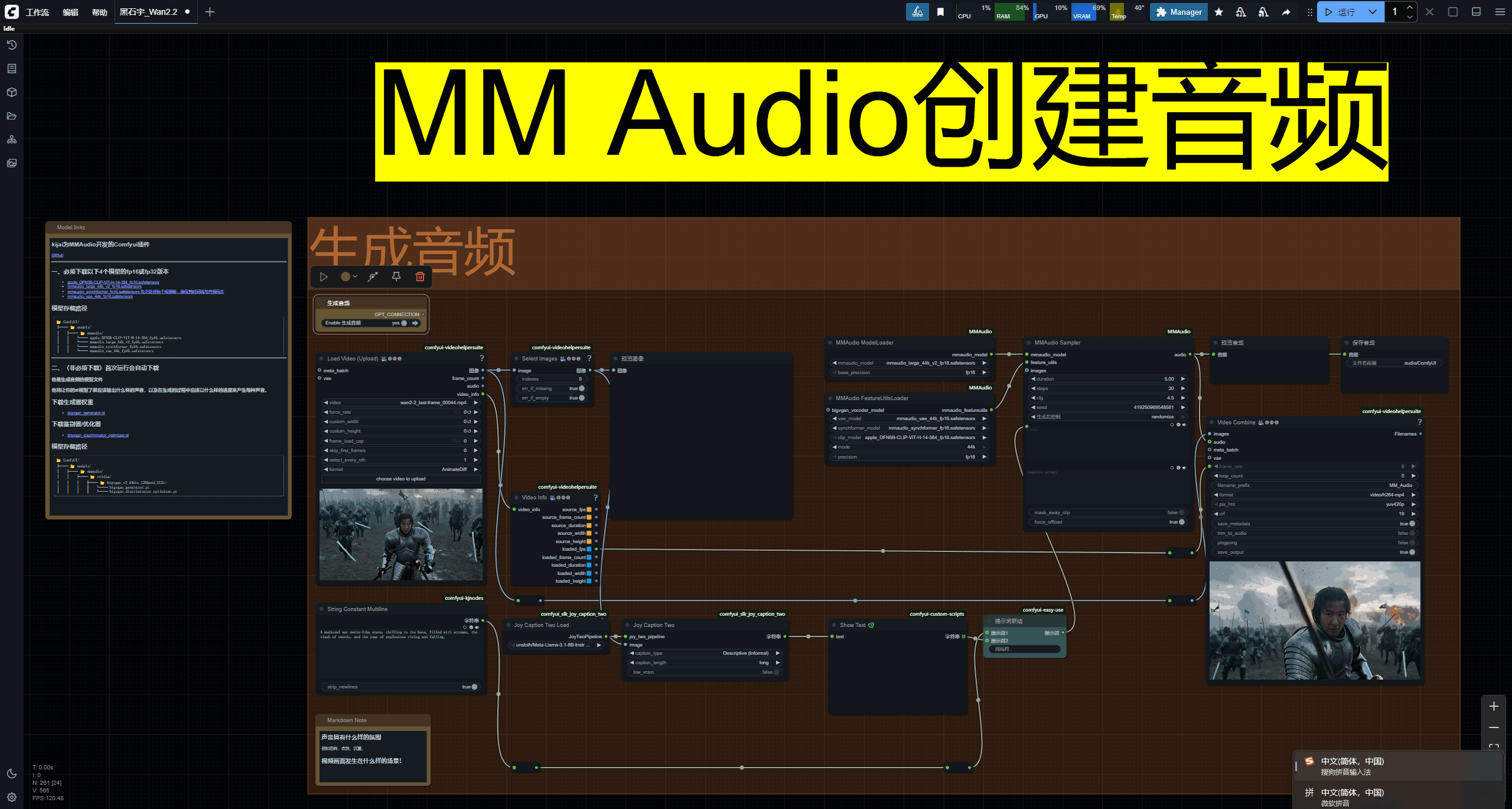
音频生成
音频生成如果你不需要可以删除!
左侧笔记节点中有模型和节点的介绍!
使用起来也十分简单!视频中有详细的讲解
安装环境命令
python_embeded\python.exe -m pip install -r ComfyUI\custom_nodes\ComfyUI-MMAudio\requirements.txt
采样器中duration属性为生成音频的时间长度,15秒之内质量是不错的。超过15秒音效的结尾会开始出现异常.
采样步数设置在25~30之间是一个合理的范围,生成的声音较好一些
cfg设置为4.5~6,过高的话会使声音更复杂而且会出现很奇怪的不属于画面中的声音。
他生成的结果并不完美,简单的视频是可以满足的,如果复杂的视频还需要我们额外处理!
Sage attention2 (不推荐)
不推荐原因
安装复杂,对新人极其不友好。
可以使用加速lora替代。
需要从新安装Comfyui和原有Comfyui不冲突,但目录太多,又要移动文件到原有Comfyui中,相当不好管理。
安装步骤
打开Github下载兼容Sage的Comfyui便捷版
https://github.com/Tavris1/ComfyUI-Easy-Install?tab=readme-ov-file
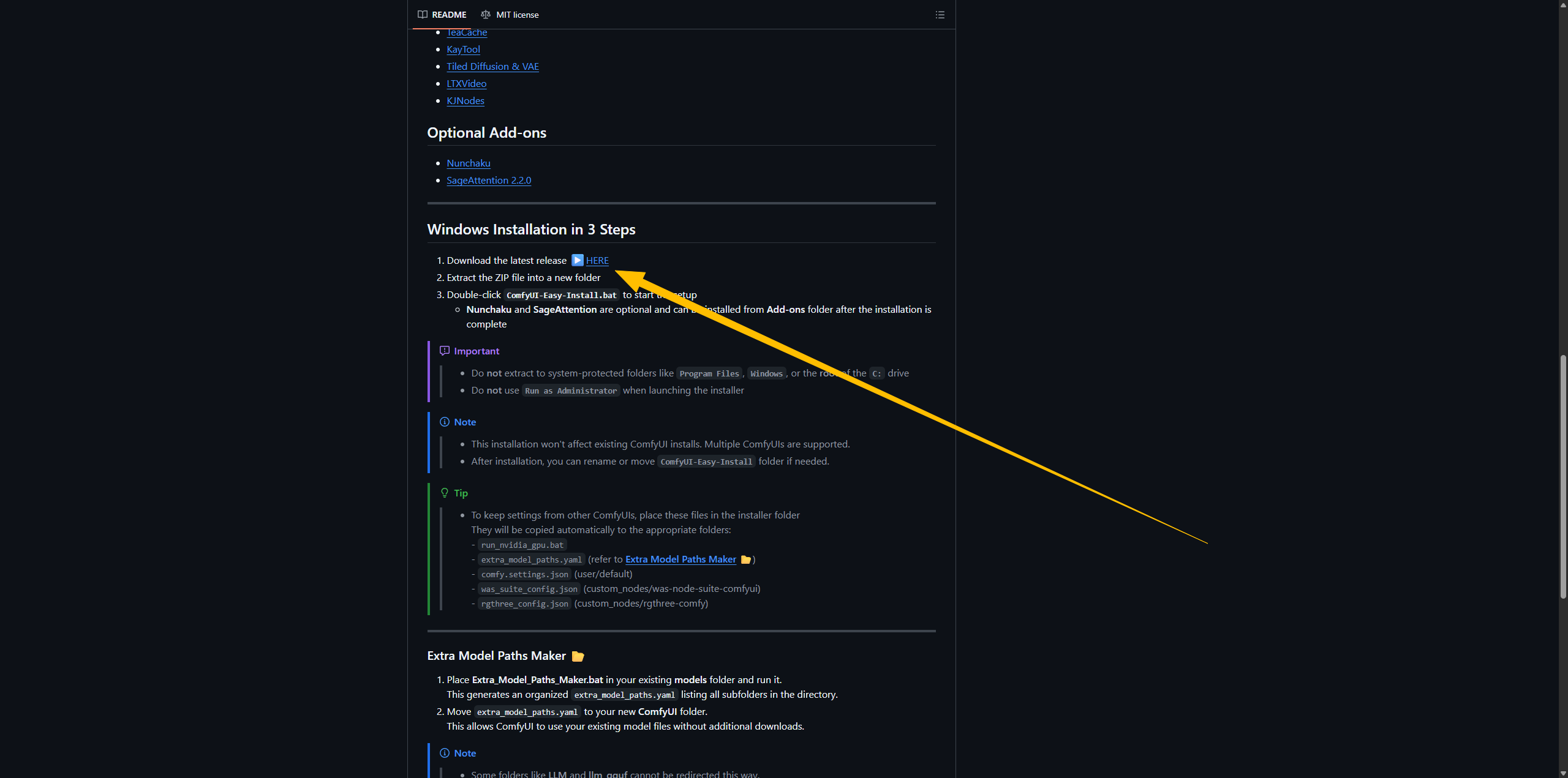
解压缩后,双击安装
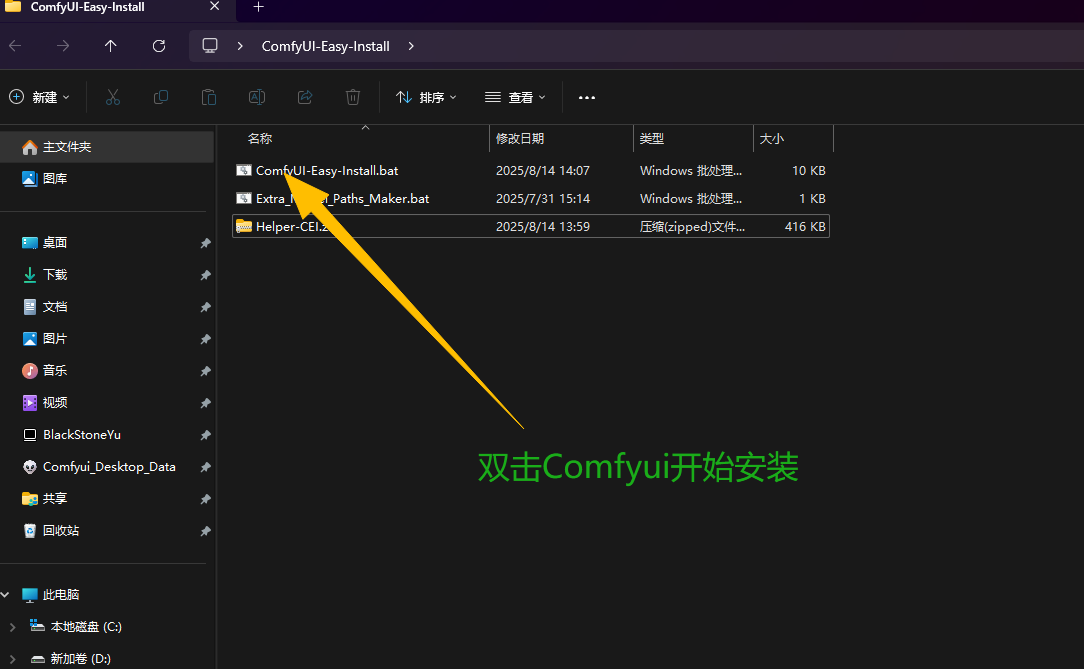
终端中自动下载
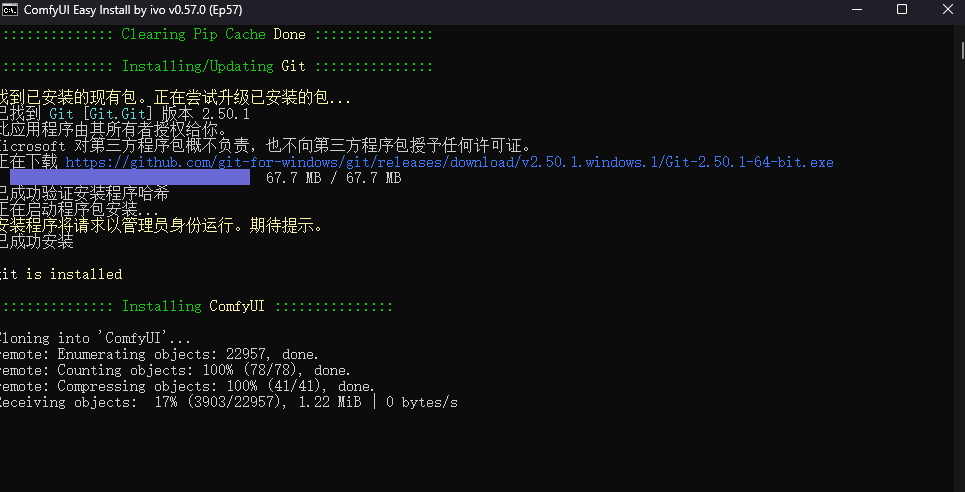
安装好后,双击进入ComfyUI-Easy-Install/Add-one目录, 然后双击SageAttention.bat运行安装文件!
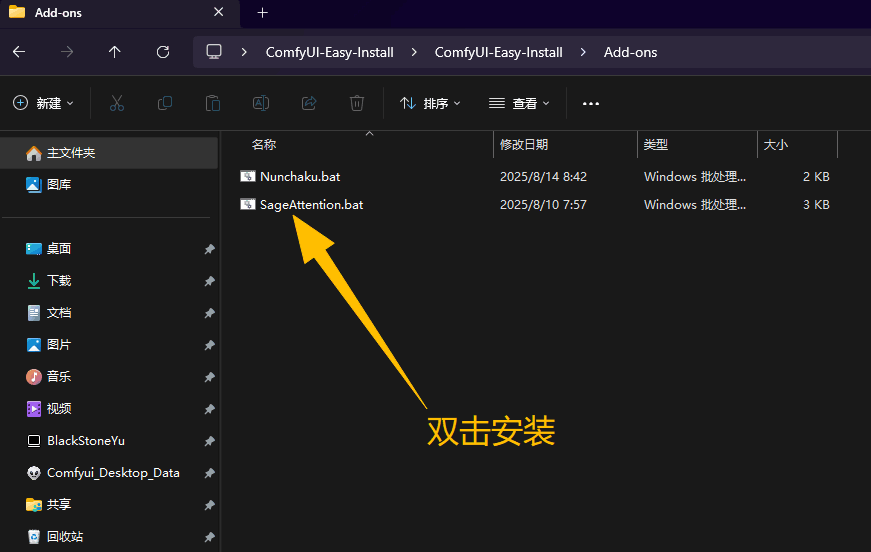
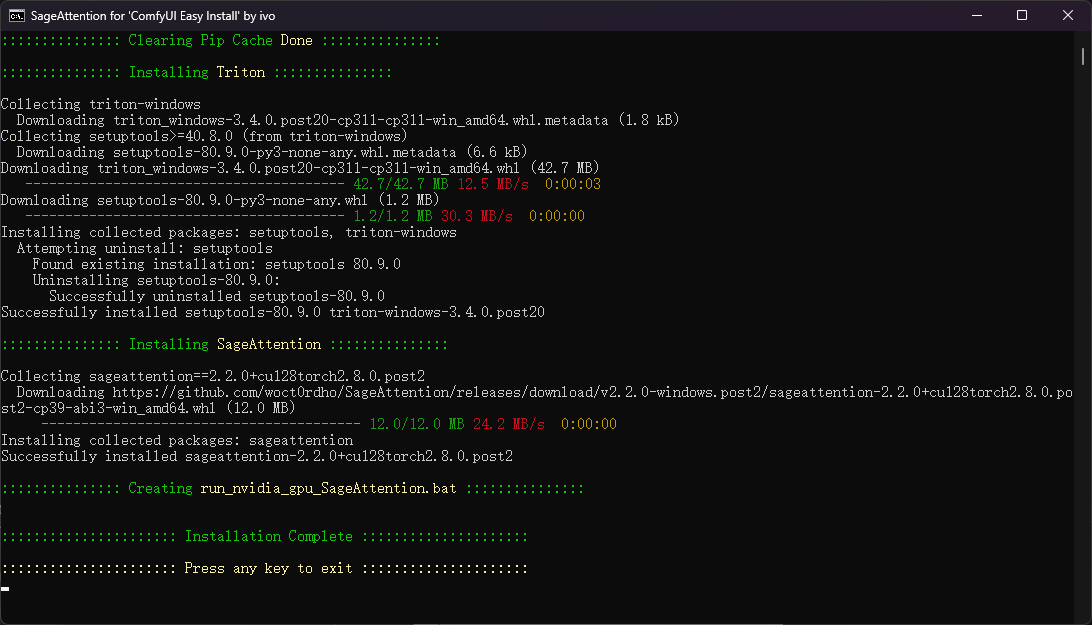
出现Installation Complete代表安装成功! 按任意键 推出即可!
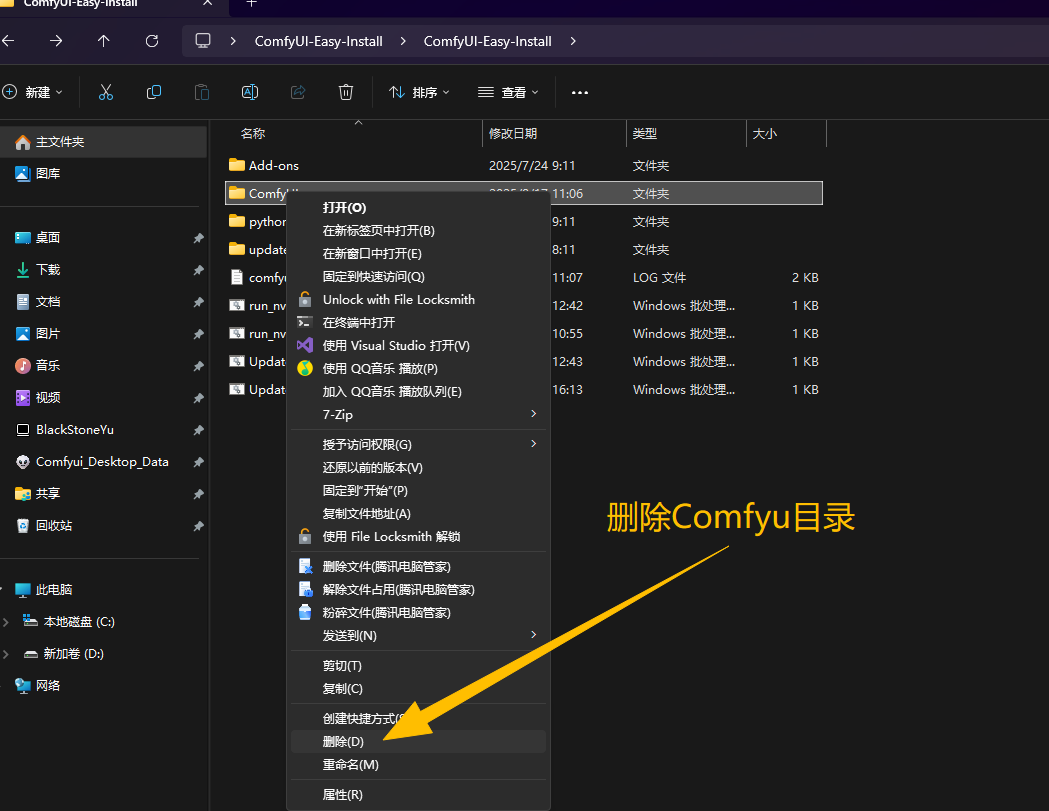
安装成功后,如果你本地电脑之前就有Comfyui并可以正常使用,那么来到ComfyUI-Easy-Install目录下,删除Comfyui目录!
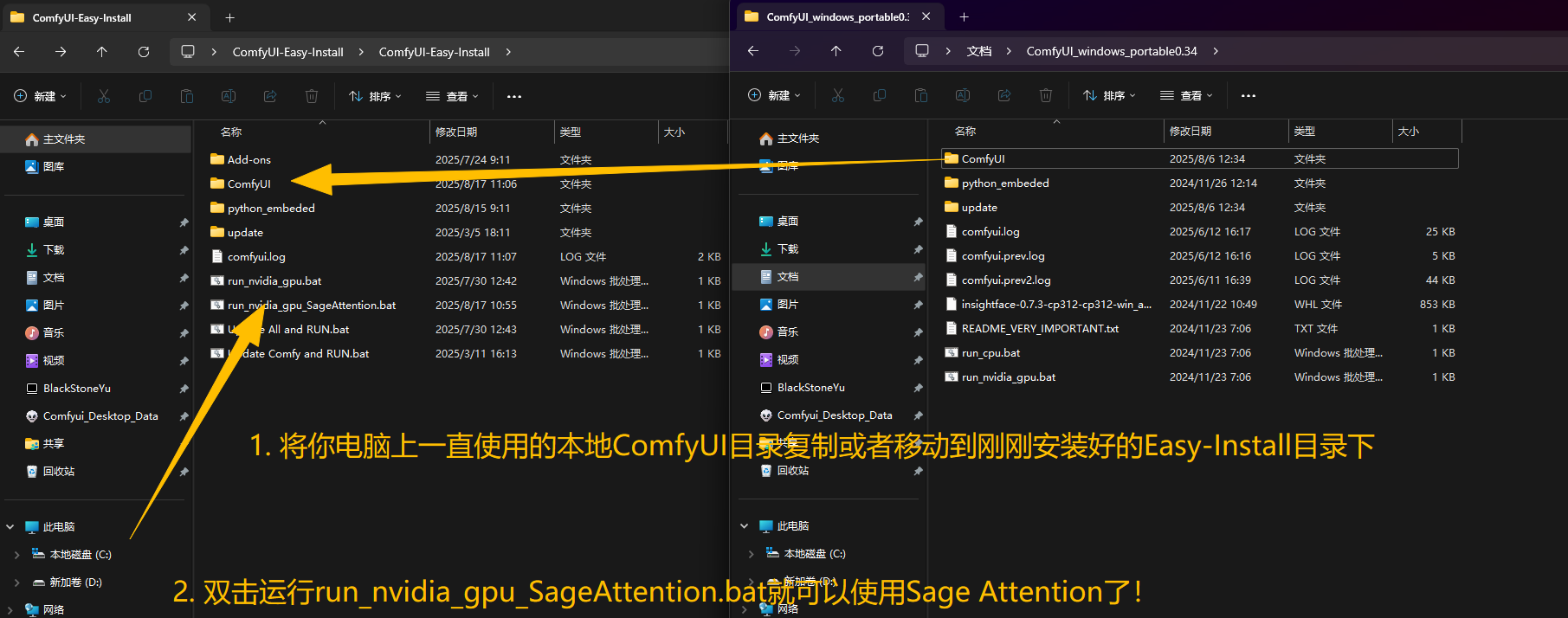
将你本地的Comfyui目录拖入到ComfyUI-Easy-Install目录下,然后双击run_nvidia_gpu_SageAttention.bat就可以运行Comfyui并使用Sage了!更多设置可以在Gifhub连接中找到!
工作流 + 素材下载
如果你喜欢我的教程,还请在点赞订阅我的B站或油管频道,让我更有动力努力下去,也希望你留下宝贵建议,谢谢!