助记词生成 && 反推随机熵
Hello , 我是09
此篇内容为我2018~2020年在【库神】工作时,对部分重要知识做的学习总结
随着比特币冲破10万美金,行业又再次兴起,希望相关从业者可以学习到你需要的内容
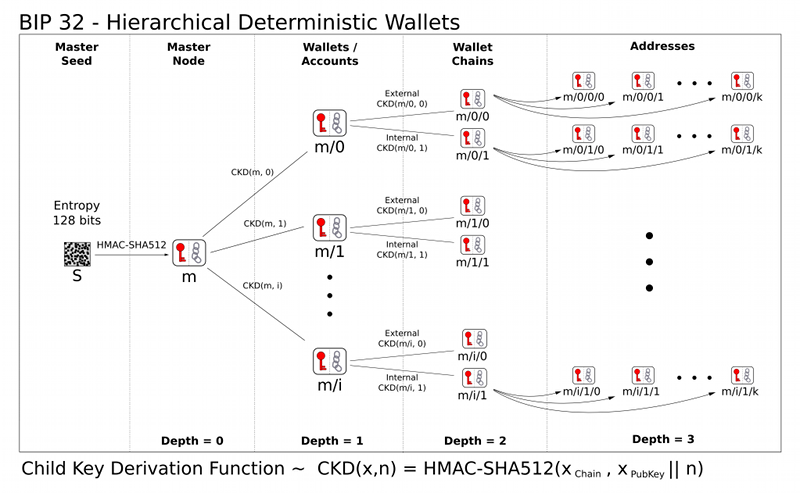
助记词 is what ?
助记词:是一种字母,单词或关联模式,可让使用的用户群体轻松记住只属于自己的重要信息。
在数字货币中,助记符采用相同的基本原则,即使用一组单词生成一个独特的钱包短语,为用户提供一个人类可读的单词格式,以便让用户备份自己的钱包,特殊场景下可以通过备份进行恢复。
数字货币钱包秘钥一般为
十六进制的64个Byte组成。备份秘钥的时候直接抄录64个字符显然是很容易产生错误的,可能直接导致钱包丢失后,无法恢复资产,安全性极底。助记词的出现恰好解决这个尴尬的问题,助记词是明文秘钥的一种表现形式。助记词的目的是为了帮助用户记忆复杂的秘钥,它一般由
12、15、18、21个单词构成, 这些单词都取自一个固定词库, 其生成顺序也是按照一定算法而来, 所以用户没必要担心随便输入12个单词就会生成一个地址。虽然助记词和Keystore都可以作为私钥的另一种表现形式, 但与Keystore不同的是, 助记词是未经加密的秘钥, 没有任何安全性可言, 任何人得到了你的助记词, 就等同于拥有了你的资产控制权。咱们目前的国内手机App钱包早期2017、2018、2019年也推出了
数字助记词、和中文助记词、但因为种种原因没有普及。(如果需要数字助记词文件和中文助记词文件的朋友可以留言)
这是英文的2048个助记词plist文件→→→→→
BIP39WordEN.plist(感兴趣的自行点击下载)
随机熵 is what ?
这里我先给大家说说什么是随机熵:
首先大家要知道:1个Byte等于
8个bit,生成的随机熵必须是32个bit的整数倍,也就等同于4个Byte的整数倍。数字货币中随机熵的长度为128~256 单位:bit。
随机熵的内容顾名思义就是随机得到的一串数字。
↓↓↓以下代码为获取OC代码获取随机熵方法↓↓↓
// 1. 实例化一个接收随机熵的容器
NSMutableData *entropy = [NSMutableData dataWithLength:16];
// 2. 随机数据
if (SecRandomCopyBytes(kSecRandomDefault, entropy.length, entropy.mutableBytes) != 0){
return nil;
}获得的随机熵为十六进制长度为32的字符串:dec9599dc873b5348824ab93c5779f81
生成助记词
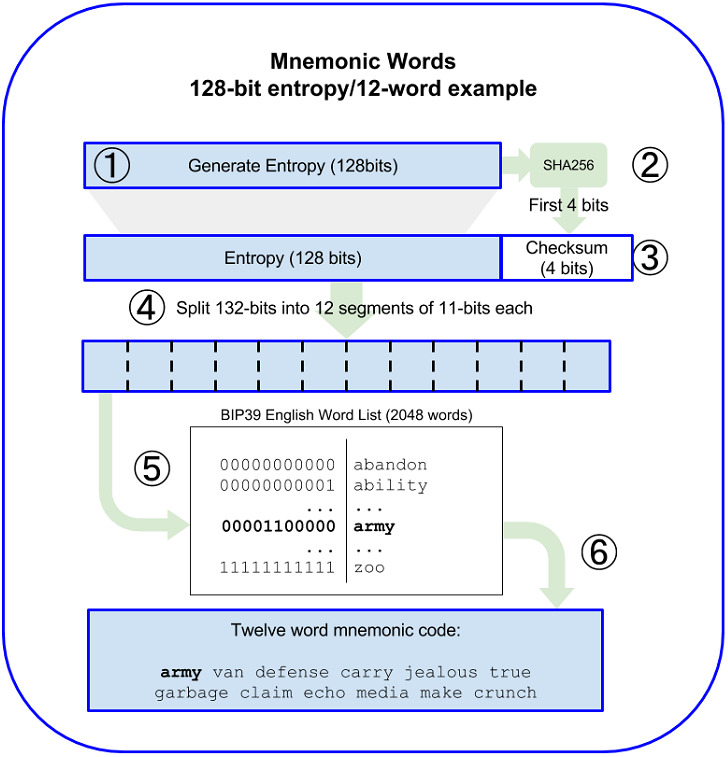
那随机熵是怎么生成助记词的呢
获取check_code: 首先将随机熵进行
hash256算法得到32个Byte特就是256bit长度的hash结果,并截取前4个bit,就是校验码。将随机熵后面拼接4个bit长度的校验码,我们就得到了完整的随机熵。
我们将完整随机熵以11bit为单位进行拆分,每11个bit转成一个10进制数,并用这个十进制数作为助记词序列的下标(助记词序列请参考助文章记词库)。
根据完整随机熵的长度,如果初始随机熵为128个bit加上校验码为132个bit,那么一共12组11bit数值,所以生成12个单词,这就是当前随机上对应的助记词。
↓↓↓OC代码如下↓↓↓
+ (NSString )p_encodePhrase:(NSData )data words:(NSArray *)wordArray
{
// 1. 随机熵长度必须为4的整数倍,data length must be a multiple of 32 bits
if (! data || (data.length % 4) != 0) return nil;
// 2. 实例化助记词库的数量
uint32_t n = (uint32_t)wordArray.count, x;
// 3. 实例化用于存储助记词的数组
NSMutableArray a = CFBridgingRelease(CFArrayCreateMutable(SecureAllocator(), data.length 3/4, &kCFTypeArrayCallBacks));
// 4. 将随机熵拼接校验码
NSMutableData *d = [NSMutableData sdk_secureDataWithData:data];
[d appendData:data.SHA256];
// 5. 推算助记词
for (int i = 0; i < data.length*3/4; i++) {
x = CFSwapInt32BigToHost(*(const uint32_t )((const uint8_t )d.bytes + i*11/8));
[a addObject:wordArray[(x >> (sizeof(x)*8 - (11 + ((i*11) % 8)))) % n]];
}
memset(&x, 0, sizeof(x));
return CFBridgingRelease(CFStringCreateByCombiningStrings(SecureAllocator(), (CFArrayRef)a, CFSTR(" ")));
}大家也可以参考下图来加强理解:
校验助记词
通过上面的学习,大家应该知道几个点
随机熵的长度是有要求的,并不是随便的长度。具体要生成的长度根据你想要得出的助记词个数来定的。
校验码的作用不仅仅是拼接后推算助记词,也是校验助记词的关键参数。
助记词库一共有
2048个单词。
↓↓↓ 知道以上这些点后,我们来做助记词的校验就相对好理解多了,直接上代码 ↓↓↓
static inline void BTCMnemonicIntegerTo11Bits(uint8_t* buf, int bitIndex, int integer) {
for (int i = 0; i < 11; i++) {
if ((integer & 0x400) == 0x400) {
BTCMnemonicSetBit(buf, bitIndex + i);
}
integer = integer << 1;
}
}
+ (BOOL)o_VerificationSeedArray:(NSArray *)words
{
if (!words) return NO;
if (words.count != 12 && words.count != 15 && words.count != 18 && words.count != 21 && words.count != 24) {
// Words count should be between 12 and 24 and be divisible by 13.
return NO;
}
NSArray* wordList = [NSArray arrayWithContentsOfFile:KEY_ENWORD_PATH];
int bitLength = (int)words.count * 11;
NSMutableData* buf = [NSMutableData dataWithLength:bitLength / 8 + ((bitLength % 8) > 0 ? 1 : 0)];
for (int i = 0; i < words.count; i++) {
NSString* word = words[i];
NSUInteger wordIndex = [wordList indexOfObject:word];
if (wordIndex == NSNotFound) {
return NO;
}
BTCMnemonicIntegerTo11Bits((uint8_t*)buf.mutableBytes, i * 11, (int)wordIndex);
}
NSData* entropy = [buf subdataWithRange:NSMakeRange(0, buf.length - 1)];
// Calculate the checksum
NSUInteger checksumLength = bitLength / 32;
NSData* checksumHash = entropy.SDK_SHA256;
uint8_t checksumByte = (uint8_t) (((0xFF << (8 - checksumLength)) & 0xFF) & (0xFF & ((int) ((uint8_t*)checksumHash.bytes)[0] )));
uint8_t lastByte = ((uint8_t*)buf.bytes)[buf.length - 1];
// Verify the checksum
if (lastByte != checksumByte) {
return NO;
}
if (entropy && entropy.bytes) {
return YES;
}else{
return NO;
}
}首先对长度进行校验—>用助记词反推出随机熵—>拆分随机熵和校验码—>重新计算随机熵的hash256—>hash结果和推出的校验码进行比对。
是不是很简单?明白了道理后真的觉得很好理解。
那么如果通过助记词推到出随机熵呢?上面的代码其实已经包括了,再单独拿出来一份代码给大家,希望大家多多支持我的博客:
+ (NSData )o_GetTouchPhraseWithSeedArray:(NSArray )seed_array
{
// 1. 对于传入的助记词数组进行数据判断
if (!seed_array) return nil;
if (seed_array.count != 12 && seed_array.count != 15 &&
seed_array.count != 18 && seed_array.count != 21 &&
seed_array.count != 24) {
// Words count should be between 12 and 24 and be divisible by 13.
return nil;
}
// 2. 初始化长度和熵
int bitLength = (int)seed_array.count * 11;
NSMutableData* buf = [NSMutableData dataWithLength:bitLength / 8 + ((bitLength % 8) > 0 ? 1 : 0)];
// 3. 循环计算熵
for (int i = 0; i < seed_array.count; i++) {
NSString* word = seed_array[i];
NSUInteger wordIndex = [wordList indexOfObject:word];
if (wordIndex == NSNotFound) {
return nil;
}
BTCMnemonicIntegerTo11Bits((uint8_t*)buf.mutableBytes, i * 11, (int)wordIndex);
}
return buf;
}总结
学习过后,大家应该明白为什么会出现助记词,和助记词隐私的重要性。
助记词的计算规则,要学会从随机熵推导出助记词,也同样要学会助记词反推会随机熵以及助记词正确性的校验。