DeepSeek - 本地部署
Hi,欢迎来到09的博客
本地部署Ai语言大模型有多种方式,在早期大家普遍使用ollama工具,作者在使用Comfyui中也使用插件链接本地ollama服务来连接大语言模型,普通用户只能通过终端使用命令进行交互。
本文主要讲解:
🤖 • 了解、选择、安装大模型可视化工具。
👾 • 根据自己的设备选择大模型压缩版本。
📂 • 配置大模型到可视化工具中并使用。
....Let's Go!
工具类型
目前流行两种大模型运行工具,网页端和客户端,他们各有优缺点,
网页端(网页端部署不需要有算力,主要通过调用api来实现与用户交互,绝大部分不支持加载本地模型)
客户端(需要本地电脑的算力来支持大模型的使用,模型一般可以选择和设备显存相匹配的压缩版本)
Lobe-Chat (网页端可视化工具,不推荐普通用户)
网页端的可视化操作,和chatgpt网页端风格相似。
目前支持十种部署方式:
Vercel 部署、Docker 部署、Docker Compose 部署、Railway 部署、Netlify 部署、
Zeabur 部署、阿里云部署、SealOS 部署、Repocloud 部署、宝塔面板部署
两个优势让它在Github中拥有53.2k Star:
💻 • 美观的UI设计
📂 • 在Docker部署的方式下是可以支持加载本地大模型的,但该功能只有在 >=v0.127.0 版本中可用,并且仅支持 Docker 部署方式才能使用

Lobe-Chat官网:https://lobehub.com/zh
github主页:https://github.com/lobehub/lobe-chat
项目部署官方指南:https://lobehub.com/zh/docs/self-hosting/start
如果你常使用ai的电脑没有高显存、拥有多个不同办公设备、熟练部署搭建服务环境,那么这种方法更适合你。
LM-Studio(客户端可视化工具,普通用户首选)
介绍:
客户端的可视化工具,和chatgpt桌面版本界面风格相似。
目前支持Windows 、Mac(M系列)、Linux三种系统。
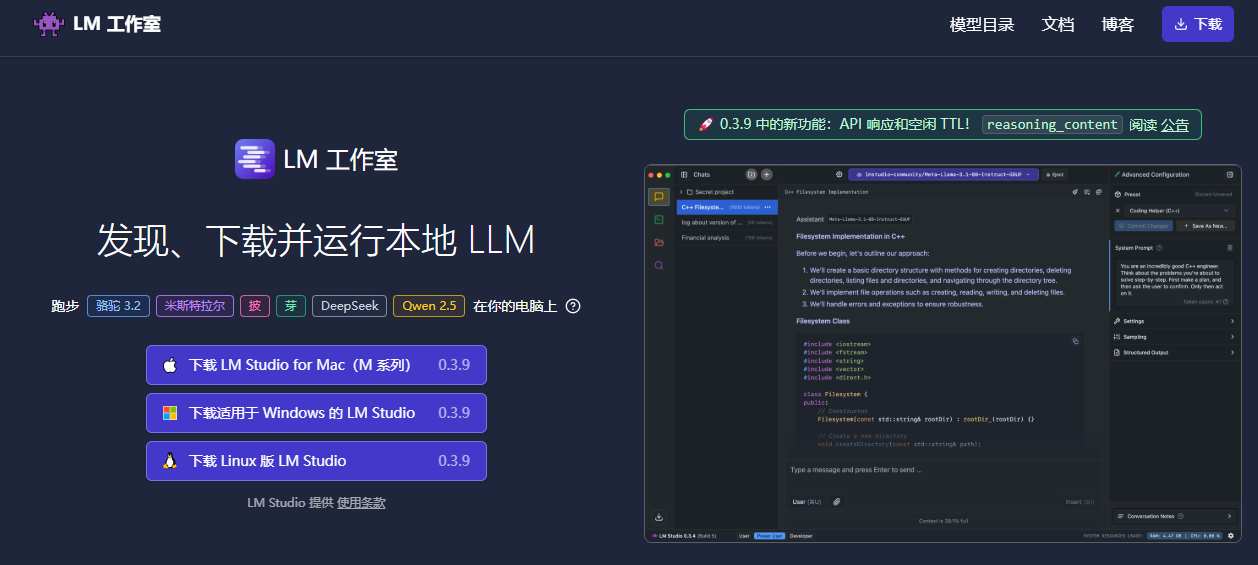
LM-Studio官网:https://lmstudio.ai/
官网Mac下载链接:LM Studio for Mac(M 系列)
官网Linux下载链接:Linux 版 LM Studio
官网Windows下载链接:Windows 的 LM Studio
(目前最新版本为0.3.9)
系统基础要求
macOS
芯片:Apple Silicon(M1/M2/M3/M4)。
需要 macOS 13.4 或更新版本(对于 MLX 型号,需要 macOS 14.0 或更新版本)。
建议使用 16GB+ RAM(您可能仍然可以在 8GB Mac 上使用 LM Studio,但请坚持使用较小的型号和适中的上下文大小)。
Linux
Linux 版 LM Studio 以 AppImage 形式分发。
需要 Ubuntu 20.04 或更高版本
Windows
LM Studio 支持基于 x64 和 ARM(Snapdragon X Elite)的系统。
LM-Studio优势:
🤖 • 在笔记本电脑上运行 LLM,完全离线
📚 • 与本地文档聊天(0.3 版新功能)
👾 • 通过应用内聊天 UI 或与 OpenAI 兼容的本地服务器使用模型
📂 • 从 Hugging Face 🤗 存储库下载任何兼容的模型文件
💻 • LM Studio 支持 Hugging Face 上的任何 GGUF Llama、Mistral、Phi、Gemma、StarCoder 等模型
并且在官网首页,开发团队描述了本地LLM的主要原因之一是隐私,而LM Studio 就是为此而设计的。您的数据将保持私密,并且只保存在您的机器本地。这对于很多对数据隐私安全有较高要求的用户是极其重要的
大模型网站
搜索引擎一搜有很多个模型下载网站,这个不重要,只要是正规平台就好
这里09只介绍两个平台
👾 • huggingface.co
Hugging Face是一家美国公司,专门开发用于构建机器学习应用的工具。该公司的代表产品是其为自然语言处理应用构建的transformers库,以及允许用户共享机器学习模型和数据集的平台。
你可以在这里找到任何模型,但需要魔法网络才可以访问。
👾 • modelscope.cn
ModelScope 魔搭社区 是一个由阿里巴巴集团推出的开源模型即服务(MaaS)平台,旨在简化模型应用过程,为AI开发者提供灵活、易用、低成本的一站式模型服务产品1。
你可以在这里找到任何模型,不需要魔法网络就可以访问。
模型版本选择
在huggingface上,我们可以看到Deepseek官方发布的r1各版本模型
https://huggingface.co/collections/deepseek-ai/deepseek-r1-678e1e131c0169c0bc89728d
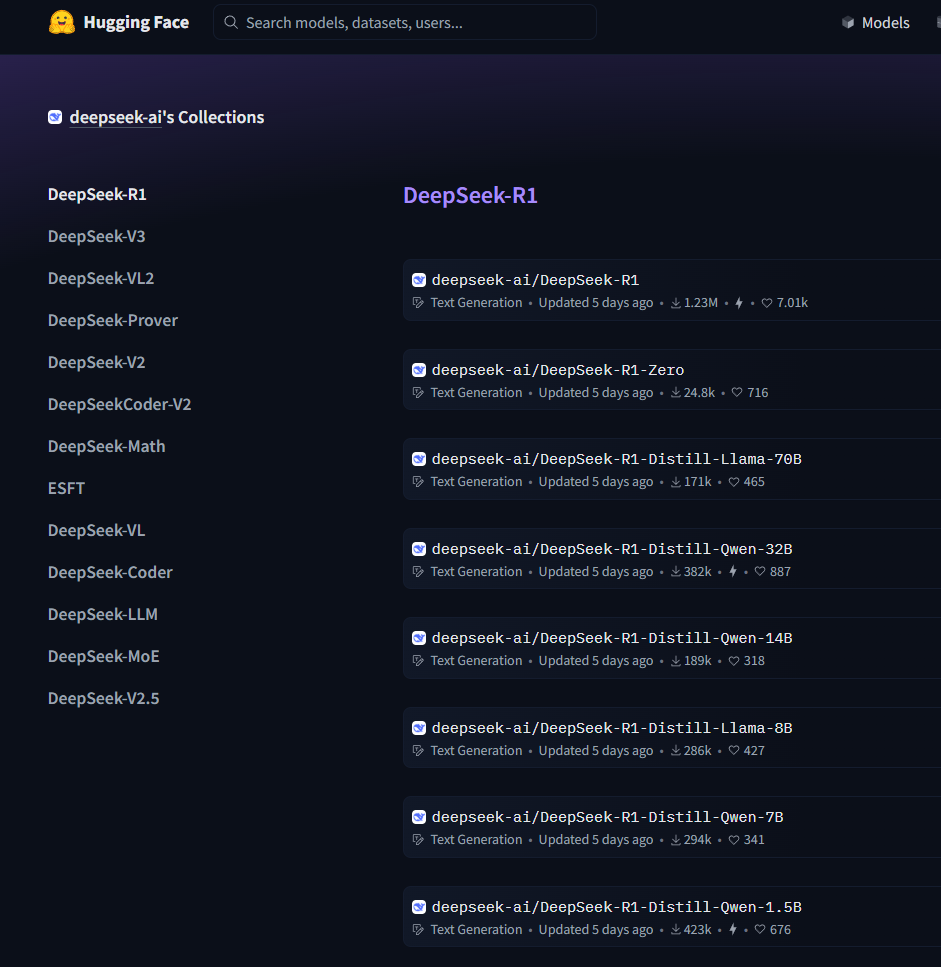
我们可以看到模型分为70B、32B、14B
deepseek-r1的基础大模型是671B,1.5b、7b、8b、14b、32b、70b是蒸馏后的小模型,他们区别主要体现在参数规模、模型容量、性能表现、准确性、训练成本、推理成本和不同使用场景。
参数规模
参数规模的区别,模型越大参数数量逐渐增多,参数数量越多,模型能够学习和表示的知识就越丰富,理论上可以处理更复杂的任务,对各种语言现象和语义理解的能力也更强。比如在回答复杂的逻辑推理问题、处理长文本上下文信息时,70B的模型可能会比1.5B的模型表现得更出色。
📂 • 671B:参数数量最多,模型容量极大,能够学习和记忆海量的知识与信息,对各种复杂语言模式和语义关系的捕捉能力最强。
📂 • 1.5B-70B:参数数量相对少很多,模型容量依次递增,捕捉语言知识和语义关系的能力也逐渐增强,但整体不如671B模型丰富。
准确性和泛化能力
随着模型规模的增大,在各种基准测试和实际应用中的准确性通常会有所提高。例如在回答事实性问题、进行文本生成等任务时,大规模的模型如 70B、32B 可能更容易给出准确和合理的答案,并且对于未曾见过的数据和任务的泛化能力也更强。小模型如 1.5B、7B 在一些简单任务上可能表现尚可,但遇到复杂或罕见的问题时,准确性可能会降低。
📂 • 671B:在各类任务上的准确性通常更高,如在数学推理、复杂逻辑问题解决、长文本理解与生成等方面,能更准确地给出答案和合理的解释。
📂 • 1.5B-70B:随着参数增加准确性逐步提升,但小参数模型在面对复杂任务或罕见问题时,准确性相对较差,如 1.5B、7B、8B 模型可能在一些简单任务上表现尚可,但遇到复杂问题容易出错。
训练成本
模型参数越多,训练所需的计算资源、时间和数据量就越大。训练70B的模型需要大量的GPU计算资源和更长的训练时间,相比之下,1.5B的模型训练成本要低得多。
📂 • 671B:训练需要大量的计算资源,如众多的高性能 GPU,训练时间极长,并且需要海量的数据来支撑,训练成本极高。
📂 • 1.5B-70B:训练所需的计算资源和时间相对少很多,对数据量的需求也相对较小,训练成本较低。
推理成本
推理成本在实际应用中,推理阶段大模型需要更多的内存和计算时间来生成结果。例如在部署到本地设备或实时交互场景中,1.5B、7B等较小模型可能更容易满足低延迟、低功耗的要求,而 70B、32B等大模型可能需要更高性能的硬件支持,或者在推理时采用量化等技术来降低资源需求。
📂 • 671B:推理时需要更多的内存来加载模型参数,生成结果的计算时间也较长,对硬件性能要求很高。
📂 • 1.5B-70B:在推理时对硬件要求相对较低,加载速度更快,生成结果的时间更短,能更快速地给出响应。
适用场景
轻量级应用,需要快速响应需求可以选择1.5B、7B 这样的小模型可以快速加载和运行,能够在较短时间内给出结果,满足用户的即时需求,小模型适合一些对响应速度要求高、硬件资源有限的场景,如手机端的智能助手、简单的文本生成工具等;在科研、学术研究、专业内容创作等对准确性和深度要求较高的领域,选择70B、32B等大模型更适合。
📂 • 671B:适用于对准确性和性能要求极高、对成本不敏感的场景,如大型科研机构进行前沿科学研究、大型企业进行复杂的商业决策分析等。
📂 • 1.5B-7B:适合对响应速度要求高、硬件资源有限的场景,如移动端的简单智能助手、轻量级的文本生成工具等,可快速加载和运行。
📂 • 8B-14B:可用于一些对模型性能有一定要求,但又没有超高性能硬件支持的场景,如小型企业的日常文本处理、普通的智能客服等。
📂 • 32B-70B:能满足一些对准确性有较高要求,同时硬件条件相对较好的场景,如专业领域的知识问答系统、中等规模的内容创作平台等。
gguf格式简单介绍
综上所示,我们普通家用设备,最适合使用的是1.5B~14B的模型
但1.5B~14B的模型还是需要较高的设备资源,普通电脑本地运行还是会很慢,所以我们可以使用gguf格式的模型.
gguf是一种二进制格式,针对快速加载和保存模型进行了优化,使其在推理方面非常高效。
下面是14B的DeepSeek-R1模型的gguf格式列表,大家可以从表格中清晰的看出来他们之间的区别:
选择适合的模型
通过上面的列表我们可以发现,越小的模型质量就会越差,那么如何选择适合自己的gguf模型呢?
超级简单:
设备显存 > 模型文件大小= 能用
设备显存 > (模型文件大小 - 2GB)= 流畅使用
例如:
我的显卡是16GB显存,那么从上面gguf列表中文件大小小于16GB的模型我都可以使用
如果我选择15.7GB的DeepSeek-R1-Distill-Qwen-14B-Q8_0.gguf是可以使用的,但是不是十分流畅,尤其是电脑再打开其他占用显存资源的软件后。
如果我选择12.12GB的DeepSeek-R1-Distill-Qwen-14B-Q6_K.gguf使用起来会十分流畅,并且质量几乎没有任何差别。
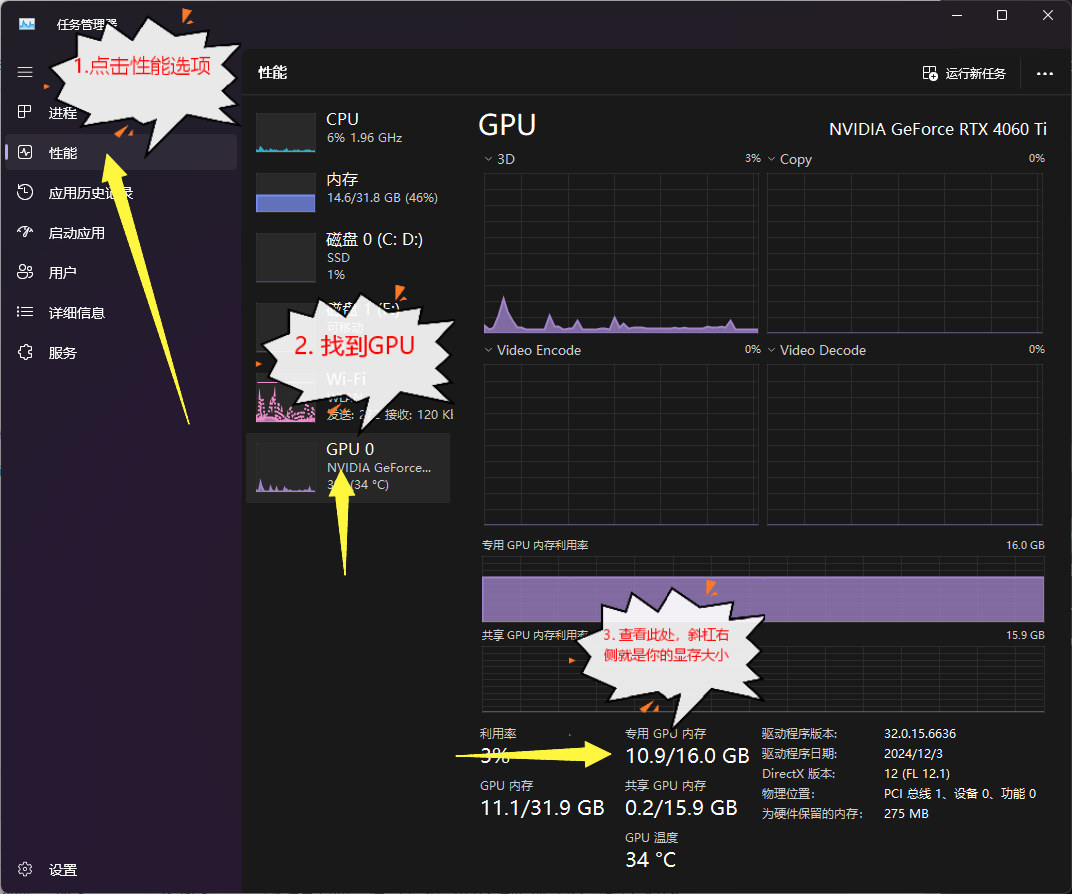
如果你不知道自己的GPU显存,那么
当然09也帮大家总结了一份列表,大家可以根据自己的显存大小,点击对应的模型直接下载使用
如何查看自己的显存
🤖 • 这个是简洁的显卡显存对照表
🤖 • 如果你的显卡不在表格内,或者你还是无法确定自己的型号,那么可以打开任务管理器,然后按下图所示就可以知道自己的显存大小
...end
还有其他的问题,欢迎留言讨论。